Le DDD pour « Domain-Driven Design » est appelé en français « Conception pilotée par le domaine ».
(À la place de « pilotée par le domaine », on pourrait utiliser orientée, motivée, justifiée…)
Les experts en code se sont tous lancés dedans lorsqu’il a fallu créer du code stable et maintenable.
Avec cet acronyme, la conception de notre application toute entière est définie sur le design du domaine.
En quelques mots, il s’agit de représenter le métier directement dans le code. Plutôt que de coder le métier.
DDD, c’est une philosophie de conception, on se base sur le métier pour assembler la solution que l’on apporte au business, autrement dit notre code.
Ainsi, la structure, le nom des classes, des champs, les actions des fonctions : tout ceci doit refléter le métier.
Dernièrement, je code énormément avec l’IA, et le fait de vouloir retranscrire le métier dans le code aide énormément l’IA à comprendre notre intention, le code généré est 10x plus qualitatif.
Dans le meilleur des mondes, une personne du métier doit presque être capable de comprendre l’intention du code qu’elle est en train de regarder.
Mais le Domain-Driven Design, c’est avant tout la compréhension du métier par l’ensemble de l’équipe.
Plus qu’une technique, c’est une heuristique de conception : on va aller chercher une intuition sur le code métier à produire.
Tout d’abord, accordons-nous sur ce que DDD qui ne signifie PAS :
Domain Driven Development
Development Driven Design
Development Domain Design
Driven Development Design
…
En fait, techniquement « Domain Driven Design » n’est pas bon non plus car il manque un -.
On devrait donc l’écrire « Domain-Driven Design ».
(Le terme français « conception dirigée par le domaine » c’est bien aussi.)
Le tiret fait encore plus sens quand on comprend qu’un des objectifs de DDD est de modéliser le domaine (métier) dans notre code.
Pour les développeurs : Le Domain-Driven Design c’est avant tout de transcrire l’intention du métier dans le code.
Pour les personnes du métier : C’est avant tout de faire comprendre le cœur du métier à l’équipe technique, de façon à ce que le métier soit implémenté telle qu’elle dans le code, au plus proche de leurs exigences.
Donc, DDD est une technique de conception logicielle, comme Merise par exemple (qu’on a tous étudié en cours).
Le Domain Driven Design n'est donc ni une techno, ni une méthodologie, ni un outil.
Le DDD se concentre sur le fait de donner au domaine métier plus d’importance qu’à la hype autour d’une technologie en particulier.
Peu importe que tu utilises PHP, Java, Ruby ou Python pour répondre au besoin du client…
Ce qui compte, c’est comment tu vas résoudre le problème du business.
La conception pilotée par le métier au cœur du code
DDD veut remettre la problématique du métier au coeur du code source qu’écrivent les développeurs.
La conception du logiciel doit être pilotée par le métier, littéralement.
C’est-à-dire que le code écrit doit refléter non pas des termes techniques…
Mais l’intention métier, la réponse à la problématique donnée.
Car, être développeur, ce n'est pas "que" coder !
En tant que développeur on est souvent spécialisé dans une techno, une architecture, un framework.
Mais ce dont a besoin le client, c’est que le développeur comprenne son métier, ses problématiques, ses enjeux…
Pour qu’il puisse coder en réponse à cette problématique.
Le but de DDD en une image.
À gauche les gens du métier qui ont une problématique bien spécifique et qui parle un langage métier…
À droite les gens de la tech qui parlent… technos !
Belle caricature hein ?
Mais cette frontière entre le développeur et le business est réelle en entreprise.
Tu trouves ça si éloigné de la réalité toi ?
Pour moi, être développeur, c'est avant tout répondre à une exigence métier.
Pour avoir bossé avec un grand groupe dans l’artisanat, je comprends beaucoup mieux pour avoir baigné dedans.
Aux alentours d’une conversation, je peux même faire illusion en sortant 2 ou 3 termes très spécifiques au métier donné.
C’est grâce à ça que j’ai pu satisfaire les besoins du client et plus encore : car je le comprenais, lui et ses problèmes à résoudre.
DDD et les autres techniques de conception
DDD n’est pas la seule option pour designer des logiciels.
D’autres méthodologies (ou approches de développement logiciel) existent et s’en rapprochent.
En voici quelques-unes :
DDD : Domain-Driven Design (Conception dirigée par le domaine – celle expliquée dans cet article)
MDD : Model-Driven Development (Développement dirigé par le modèle)
MBE : Model-Based Engineering (Ingénierie fondé sur le modèle)
MBP : Model-Based Programming (Programmation fondé sur le modèle)
MDAD : Model-Driven Application Development (Développement d’application dirigé par le modèle)
MBAD : Model-Based Application Development : (Développement d’application fondé sur le modèle)
MBP : Model Based Programming (Programmation fondée sur le modèle) MDSD : Model-Driven Software Development (Développement logiciel dirigé par le modèle)
On pourrait penser qu’ils font à peu près la même chose mais ce n’est pas le cas.
https://www.omg.org/mda/
DDD se concentre plus sur la retranscription du besoin client dans le code, sans forcément parler technique.
Car les techniques données par DDD s'appuient essentiellement sur les "strategical patterns" plus que sur les "tactical patterns".
En d’autres termes, on peut parler DDD sans parler technique.
Des outils comme le MDD (Conception Dirigée par le Modèle) s’appuient sur des patterns techniques.
Or la conception dirigée par le domaine (DDD) ne s’occupe pas du modèle en première intention.
Ni de l’architecture.
Ni de la technique en général.
Elle se concentre réellement sur le domaine, aka le métier.
Data-Driven Design vs Domain-Driven Design
La plupart des modèles que j’ai conçus dans ma vie de développeurs étaient « Data-Driven ».
C’est-à-dire basés sur les données.
Tu commences par faire l’UML, tes relations, tu crées tes entités Doctrine…
ET SEULEMENT APRÈS CELA, tu commences à coder tes actions métiers.
UML pour modéliser ses tables de base de données : https://www.omg.org/spec/UML/2.5.1/PDF
Créer ses entités en base de données : https://symfony.com/doc/current/doctrine/associations.html
Or avec un modèle « Domain-Driven », tu te bases d’abord sur le métier.
C’est-à-dire que tu pars d’abord des actions métier pour ensuite modéliser ton modèle de données.
Pas d’over-ingenierie donc !
Objectif DDD : Faire un projet au plus proche du métier
Le Domain Driven Design veille à ce que le modèle de données du métier soit exprimé dans le langage métier (mais aussi dans le code).
Langage métier défini ensemble, par le business ET les développeurs.
Cela implique parfois de changer d’architecture, mais surtout de communiquer davantage en amont avec le métier.
Le Domain Driven Design est une manière de penser et de voir le projet, il doit être drivé par une réelle envie retranscrire le savoir du métier directement dans le code.
La communication est la clef pour son utilisation.
Personnellement, je ne compte plus le nombre de projets que j’ai vu mal conçu, mal compris, mal évalué…
Notamment car le besoin n’avait pas été compris !
C’est ça, que DDD essaye de résoudre.
Pour illustrer ça en une image (que tu as déjà dû voir passer 1000 fois…).
« Ce que le client voulait vraiment » : http://www.projectcartoon.com/cartoon/2
Avec DDD, on livrera quelque chose qu’attend le client car on aura compris dès le début ce qu’il souhaitait.
Qui a inventé le DDD ?
Le DDD a été créé par Eric Evans en 2003 suite à la sortie de son livre « Le blue book », « Tackling Complexity in the Heart of Software ».
Il présente ce livre comme étant le fruit de 20 années de bonnes pratiques de développement tirées au sein de la communauté de la programmation orientée objet et du software craftsmanship.
Domain-Driven Design: Tackling Complexity in the Heart of Software
Ce livre présente un ensemble de règles à suivre sur des principes, des schémas, des idées, des pratiques qui n’ont toutes qu’un seul but :
Enrichir dans le code la compréhension du besoin métier.
DDD permet aussi d’arriver à un langage commun, compréhensible par tous les membres de l’équipe.
Du client, du business, du métier, du chef de projet, du développeur…
Pour la petite histoire, Eric Evans a créé sa société en l’appelant « Domain Language« .
C’est dire si le DDD n’est pas technique en premier lieu et est destiné à la compréhension du métier avant tout !
Domain-Driven Design, quand l’utiliser ?
La conception dirigée par le domaine est un bel outil pour que le business et les développeurs se comprennent.
Ce qui n’est pas toujours évident…
Microsoft recommande d’utiliser DDD lorsque le domaine métier est complexe et a besoin d’être très bien compris par les développeurs pour la solution développée soit efficace.
Malheureusement en tant que développeur, on peut souvent coder des actions métiers dont on ne comprend souvent pas grand chose.
C’est là que le Domain-Driven Design vient nous aider, nous les devs !
Car le salut ne vient pas des frameworks et des technos…
Il vient en premier lieu de notre tête, de notre manière de voir les choses.
Alors, parfois il vaut mieux supprimer tout ou partie pour repartir de bonnes bases…
Parfois pas.
C’est difficile de juger sans voir le code.
Grâce à DDD, comme tu abstrais ton code métier de tout lien technique (aussi grâce à la clean architecture), tu es censé pouvoir rapidement mettre à niveau ton application.
Il existe aussi des solutions pour se sortir du code legacy et restructurer un projet qui part en cacahuète comme les Bubble Contexts que l’on verra un peu après.
Gérer du code legacy c’est un sacré boulot et DDD peut t’y aider.
Avantages et inconvénients de DDD
Pour en finir avec cette partie sur ce qu’est le Domain-Driven Design, je te propose de lister les avantages et les inconvénients de DDD.
De cette manière, tu sauras si tu dois utiliser les techniques préconisées par DDD dans tes projets.
Avantages du Domain Driven Design 👍
Place l’équipe technique au centre du domaine métier : les développeurs savent ce qu’ils codent et pourquoi, ils comprennent le métier et détiennent un réel savoir.
Communication : On gagne du temps en communication étant donné que l’on parle de la même chose, on limite les problèmes d’implémentation.
Onboarding et compréhension du code : DDD insiste vers le fait que la structure de code devrait être comprise par le métier, cela pousse vers la création de fichiers compréhensibles, ce qui facilite encore plus la compréhension du métier par les (nouveaux) devs.
Extensible : Le domaine est souvent modulaire, ce qui le rend flexible, facile à mettre à jour par rapport aux nouveaux changements demandés.
Testable : Comme on utilise les principes de la POO et que le métier est fortement intégré dans le modèle, on peut tester les objets directement et indépendamment.
Un couplage faible nous permet aussi d’isoler les modules pour les rendre indépendants.
Maintenance : A priori les évolutions futures du projet ne doivent pas remettre en question les choix initiaux en termes de conception – grâce à l’architecture modulaire (et l’Anti-Corrumption Layer) on peut supprimer/modifier des modules assez facilement.
Technicité : DDD n’est pas vraiment technique, les outils proposés sont nombreux et rien ne t’empêche d’utiliser certaines techniques stratégiques de DDD seuls (comme l’Ubiquitous Language).
Outils : Certains outils tactiques comme les ValueType ne coûtent pas grand-chose à implémenter… pourquoi s’en passer ?
Stabilité : Généralement on choisit des technologies stables déjà éprouvées pour le Core Domain, on ne prend pas de risque.
Inconvénients du Domain Driven Design 👎
Investissement : Requière un investissement de la part de tous les membres de l’équipe (métiers ET techs) sous toutes ses formes.
Techniquement pointu : Il faut être drivé par des développeurs seniors, ne serait-ce que pour la mise en place de l’architecture.
Coût : Cela prend plus de temps à concevoir, créer, designer, coder… C’est donc plus cher.
Liberté de conception : DDD essaye de structurer le code en fonction du métier, pas en fonction de ce que pense le développeur qui écrit le code à l’instant T.
Il faut réapprendre à coder POUR le métier.
Personnellement, je prends des concepts ou des outils du Domain-Driven Design dans mon boulot de développeur que j’incorpore un peu plus chaque jour…
Même si le Domain-Driven Design dans son intégralité n’est pas fait pour mon projet actuel, j’essaye de m’enrichir avec certains des outils qu’il propose.
Petit à petit…
Patterns stratégiques de DDD
Ce sont les patterns les plus importants.
Tu as peut-être déjà entendu dire que le Domain-Driven Design était avant tout stratégique plus que technique ?
Eh bien c’est totalement vrai !
Avant de commencer à coder il faut voir où on va.
Il serait louche de commencer à coder quelque chose si on ne sait pas de quoi on parle en amont…
Partant de ce principe, le DDD veut d’abord faire monter les équipes en compétence sur le domaine métier grâce à certains outils ou méthodes (les patterns stratégiques).
Une fois que cette partie est totalement comprise, on essayera de retranscrire au mieux cette partie métier dans le code.
Personnellement j’adore la technique et je me suis toujours jeté dessus…
C’est une erreur que DDD m’a bien fait comprendre.
Les patterns stratégiques du Domain-Driven Design (tirés du livre « DDD Vite Fait »)
Ubiquitous Language ou Langage Ubiquitaire
Ce pattern stratégique est mis en premier car c’est probablement le point le plus important du Domain-Driven Design.
Le langage partagé permet de fournir un vocabulaire issu du métier qui est commun (le même) entre le métier et l'équipe technique.
Ce langage commun permet de mettre des mots précis sur le domaine d’expertise et de s’entendre sur les bons termes à utiliser lors des communications.
J’aime bien cette image, tout le monde pense être aligné mais quand chacun montre ses idées, on se rend compte que finalement, personne n’avait la même chose en tête.
La principale inquiétude pour les développeurs c’est d’avoir du code en « franglais », et ça je le comprends totalement.
getDateDeDepartDuTrain();, ça ne fait pas rêver comme nom de fonction.
Cependant…
Coder en français est une véritable option
Tout est une question de complexité métier.
Et pas besoin de partir bien loin, regarde cet exemple tout simple :
Tu dois entrer le $nom d’une personne, faut-il choisir $name, $firstname, $lastname, $givenName ou $famillyName ?
Je ne compte plus le nombre d’incompréhension sur ce sujet.
Pour un truc aussi simple en plus !
Alors imagine quand le métier est complexe, ça devient souvent le bordel si personne n’est ok sur les bons termes.
getNomDeFamille(); et c’est réglé.
Là pour le coup tu te dis peut-être que mon exemple il est naze parce que c’est facile comme terme (très générique).
Et tu n’aurais pas vraiment tort.
Exemple de code en français qui nous aurait fait gagner en qualité
Pour te donner un exemple plus parlant, j’ai bossé sur un site de mise en relation d’installateurs avec des particuliers.
Pour le terme « Installateur » en français, on pouvait retrouver dans le code des termes :
❌ Ambigus : Installer
❌ Faux : Installater
✅ Traduits : Fitter
✅ Justes : Installateur
❌ Dupliquées : Installator
Alors même pour un terme métier simple, si on s’était accordé sur le terme français « installateur », on aurait été beaucoup plus efficace.
Alors oui ça dépend de l’équipe dev qui pour le coup était composée de 3 prestataires externes : on a manqué de communication.
Mais est-ce que cela ne nous aurait pas aidés de coder en français ?
Faut-il coder en français ou en anglais ?
Je me pose la question.
Je te pose la question aussi.
Toujours est-il que l’on a créé du code legacy dégueu dès le début du projet par manque de langage commun/partagé dans le code.
Traduire les termes métiers ?
Une barrière à l’utilisation de l’ubiquitous language peut-être la traduction des différents modèles vers l’anglais.
Certaines équipes refusent catégoriquement de faire du français dans leur code et ça peut se comprendre.
Notamment si le développement est internationalisé, ça peut poser des soucis.
L'équipe de dev doit se mettre d'accord sur les bonnes traductions à utiliser, mais pas seulement.
Comme DDD est utilisé sur des domaines métiers complexes, il faut être capable de jongler rapidement dans sa tête d’un modèle français à un modèle anglais…
Ce qui n’est pas toujours facile.
Gros point d’attention donc.
Si on a besoin d’un lexique pour s’y retrouver, on peut se poser la question de l’utilité de l’Ubiquitous Language.
Il vaut peut-être mieux parfois « franciser » des termes plutôt que de tenter une traduction foireuse…
L’Ubiquitous Language doit être défini le plus tôt possible.
Cela paraît simple mais c’est comme toute base, cela met un moment à se roder.
Si le projet a déjà démarré, on essayera au mieux de palier à ça en s’accordant rapidement avec le métier sur les futurs termes métiers à utiliser.
Il ne faut pas hésiter à rechanger le code déjà présent (refactoring) pour uniformiser le code sur un terme métier, traduit ou non.
Quelques règles simples pour mettre en place ce langage omniprésent (enfin, ce langage partagé !) :
Avec les termes métiers
Exprimer à haute voix
Utiliser des phrases simples
Supprimer les synonymes en se forçant à n’utiliser que le terme retenu
Dans nos conversations
Éviter les digressions, se concentrer sur l’essentiel : le domaine
Supprimer les mots techniques autant que possible
Les devs doivent implémenter le modèle dans le code au plus proche de celui décrit par les experts métiers (avec les mêmes termes)
Privilégier plusieurs éléments simples pour faire des modèles plus complexes
Utiliser les termes métiers dans le code
Les experts du métier définissent la structure et les termes, les développeurs challengent et se concentrent sur les ambiguïtés ou les inconsistances du design
Bounded Context ou Contexte Borné
Un bounded contexte ou contexte borné représente une façon de voir le monde.
C’est un concept métier précis qui répond à une problématique.
La plupart du temps on a tendance à rassembler techniquement les contextes alors qu’ils ne sont pas nécessairement liés entre eux.
On doit découper notre architecture en fonction du concept métier à aborder, et non en fonction du code utilisé.
1 base de code = 1 bounded context
Le contexte borné est limité par son contexte métier.
Si des interactions existent entre les actions métiers, on se servira d’interfaces pour accéder à ces informations (peu importe le protocole d’ailleurs, même c’est souvent http).
Par principe, tu ne devrais d’ailleurs pas avoir besoin de partager du code entre tes contextes si jamais ils sont limités et clairement définis.
Néanmoins, il peut exister des cas où une lib interne répond parfaitement à plusieurs use-cases (comme une lib de chiffrement par exemple qui peut être utilisée à plusieurs endroits).
Une application n'est jamais constituée d'un seul métier, et comme c'est l'interaction entre les métiers qui constitue le logiciel, on crée souvent de nombreuses dépendances entre les différents domaines.
Un bounded context comporte donc des frontières afin de rassembler des éléments du métier entre eux.
Ce contexte borné s’occupera de gérer une fonctionnalité précise d’un domaine, comme :
la gestion des utilisateurs,
l’inventaire des produits,
la livraison…
1 Bounded Context = 1 Ubiquitous Language
C’est une notion très importante car le même nom ne se modélise pas forcément de la même façon dans chaque contexte borné.
Ces 4 termes peuvent désigner une seule et même personne utilisant l’application, ok ?
Mais suivant le métier (le domaine) qui jouera avec cet objet utilisateur, il peut avoir un nom différent dans chacun des services.
Pour le service de livraison on dit un "destinataire", mais pour la comptabilité c'est un "compte".
Même si c’est la même personne, les informations nécessaires (les champs dans l’objet) ne seront sûrement pas les mêmes !
On a délimité notre domaine au sein du bounded context.
Aucun élément externe ne viendra affecter le métier du contexte (comme une adresse de livraison pour un utilisateur du site, à l’enregistrement cela n’a sûrement aucun intérêt).
Si tu changes de contexte, tu définis les nouveaux objets du domaine.
Potentiellement, cette adresse pourra être utilisée pour :
L’enregistrement d’un utilisateur ;
La fiche d’un produit ;
Un point de livraison ;
…
Et tout un tas d’autres objets.
Si j’ai besoin de rajouter un champ « code de livraison » qui concerne uniquement un point de dépôt, comme est-ce que je fais ?
Un bounded context ne DOIT PAS en affecter un autre.
Donc si jamais on change le value object Address quelque part dans notre code, cela va affecter toutes les classes qui en dépendent.
Toutes les classes qui utilisent cet objet pour gérer les adresses…
Et est-ce que je veux ce champ pour l’adresse de l’utilisateur dans la facturation ?
Pas du tout.
Aussi, on n’est pas obligé de tout factoriser, et avoir un peu de duplications de code pour protéger mon contexte métier en cas d’évolution de l’appli est une bonne chose.
Aucune duplication n'est gratuite, car si on factorise on couple !
On peut tout de même utiliser des Shared Kernel pour les éléments réellement partagés (on voit ça juste en dessous).
Mais la plupart du temps, il vaut mieux rester dans son contexte.
Comment créer son Bounded Context ? 👇
On peut commencer par isoler des modules et des fonctionnalités dans des dossiers précis.
On partira du principe que ce module, son code et son exécution sont totalement isolés du reste de l’application ; un peu comme un service externe.
Il n’existe pas qu’une seule manière de créer un contexte partagé, mais personnellement j’aime beaucoup l’approche en packages.
Le concept du noyau partagé est simple et peut se retrouver à plusieurs niveaux de l’application.
Par exemple un Value Object Email peut être utilisable par plusieurs contextes bornés dans l’application.
Or, on ne va pas dupliquer le code de l’objet à chaque fois, cela n’aurait pas de sens.
Comment créer un Shared Kernel ? 👇
Identifie avec les autres membres des équipes chaque Bounded Context qui partage potentiellement des objects, des actions, des relations
Organise toi en amont et non pas en aval (car plus le temps passe et plus il sera difficile d’assembler le puzzle si les équipes ont trop avancé de leur côté)
L’objectif est d’éviter les doublons, alors la factorisation peut être choisie si les objets contenus dans le noyau partagé sont totalement indépendants (eux même n’ont pas ou peu de relations – ni d’attributs ou d’actions superflus)
Chaque changement dans le noyau occasionne une communication des équipes sur les changements apportés
Les éléments du noyau doivent être testés un maximum dans le noyau et en dehors car il s’agit là d’un point où potentiellement un commit peut tuer un bounded context
Le noyau partagé peut se faire globalement (EmailAddress) ou par « sous-module », comme un objet Size qui pourrait être utilisé pour des vêtements ou des chaussures, mais restant dans le core domain du Bounded Context « Produits »
Context Map ou Carte de Contextes
Par principe, un bounded context va devoir discuter avec d’autres parties de l’application.
L’interaction entre les contextes est inévitable, il ne faut pas chercher à la masquer.
Un exemple simple, c’est un flow e-commerce.
Création d’un utilisateur
Ajout d’un produit au panier
Paiment du produit
Livraison
Sans rentrer dans les détails, on peut voir que les contextes sont liés entre eux.
Mais un bounded context ne doit (en théorie) pas être dépendant d'un autre.
S’il l’est, c’est probablement que c’est le même contexte ou… qu’il a mal été découpé.
Si je reprends mon exemple, je ne dois pas avoir besoin du paiement pour livrer un produit.
Ce sont des contextes séparés car les besoins sont totalement différents.
Il faut voir cela comme un puzzle que l’on va assembler.
UpStream (U) / DownStream (D)
On récapitule : un contexte partagé aura surement besoin d’un autre contexte.
Ces deux contextes vont devoir communiquer, mais il y aura toujours une relation client -> fournisseur.
L’un donne l’information (upstream) et l’autre la reçoit (downstream).
À noter que ceci est valable pour les bounded contexts dans l’application mais, la même chose s’applique pour les autres interactions (comme un appel à un microservice externe).
Pour faire les choses bien, il faut définir la communication entre les équipes.
Si quelqu’un fait quelque chose sur une API et que ça casse les dépendances, on fait comment ?
C’est là qu’on discute de qui donne les données à qui (qui est le maître et qui est l’esclave).
Le design stratégique permet d’éviter que quelqu’un change un truc d’un côté sur une API dépendante et que l’application soit cassée.
Ainsi on définit qui est dépendant de quoi et cela met en lumière les potentiels points à problèmes.
Comment gérer les context maps ? 👇
Il faut les gérer surtout si un contexte borné a besoin de sortir de ce dernier pour jouer avec des données ET qu’il en est dépendant, qu’une fusion ou un kernel partagé n’est pas possible.
Qui a raison, qui impose son choix, qui détient un élément partagé…
Ce sont ces questions qu’il faut se poser.
On peut être tenté d’affecter une équipe projet à un bounded context et c’est très bien
Les équipes doivent discuter entre elles de l’interaction future entre leurs contextes respectifs
Comme elles sont garantes de l’intégrité de LEUR contexte, les équipes ne chercheront pas à merger leur contexte ou à intégrer des changements dans leur modèle du fait d’un autre contexte : ils restent indépendants
Un diagramme peut être utilisé pour modéliser les relations
Protéger un maximum ses contextes avec la couche anticorruption (on en parle plus bas)
Context Distillation ou Distillation du domaine
Le Domain-Driven Design se concentre encore et toujours sur le domaine…
Mais des domaines, il peut y en avoir plusieurs.
Le context distillation pattern nous propose de les catégoriser en 3 domaines :
Core Domain : Le coeur de domaine
Supporting Domain : Le domaine de support
Generic Domain : Le domaine générique
Grâce à ça, on va pouvoir affecter à un domaine une priorité, ou plutôt une importance.
Sachant que chaque domaine peut avoir un sous-domaine !
Le coeur du domaine (core domain)
Pour trouver notre coeur de domaine c’est très simple :
Qu’est-ce qui apporte de la valeur sur notre application ?
C’est ce qui fait que notre application a une plus-value, qu’on n’utilise pas une solution déjà existante ?
Quel est le domaine qui nous sépare de la concurrence et qui fait que l’on va gagner de l’argent ?
Le coeur de domaine, c'est le coeur du business.
Aussi simple que cela.
Le sous-domaine (subdomain)
Le coeur du domaine c’est le problème principal que l’on essaye de résoudre.
Pour les subdomains, ce sont les problèmes qui viennent avec notre problème principal.
Un sous-domaine est simplement un enfant d’un domaine.
Un mécanicien répare des voitures (core domain) mais a besoin de matériel pour cela (subdomain -> supporting domain)
Core Domain, c’est ce qu’apporte l’application, pourquoi tu la codes, la plus-value que tout le monde va en retirer.
Support Domain, c’est ce qui vient aider le Core Domain, il l’aide à réaliser ses actions, il est lui interchangeable et peut être remplacé (contrairement au Core Domain qui est la raison d’être du business). Cependant il est essentiel au fonctionnement du Core Domain.
Generic Domain, contient les parties « génériques » de notre application, globalement ce sont les parties du code qui sont communes à tous les logiciels et qui n’apportent pas vraiment de plus-value métier (gérer des utilisateurs et les autorisations c’est bien, indispensable même, mais ce n’est pas grâce à ça que ton client va faire fortune).
Comment utiliser le contexte distillation ? 👇
C’est bien beau de connaître son coeur de domaine, mais maintenant, on fait quoi ?
Le Core Domain doit être pris en charge par les « meilleurs développeurs » de l’équipe ou du moins des seniors
Celui-ci doit être testé de fond en comble car c’est sa stabilité et son efficacité qui rapporte de l’argent
Comme il est critique (s’il tombe la boîte en souffrira lourdement), on prendra soin de sécuriser chaque livraison et de mettre réellement l’accent sur la qualité de code
On évitera de baser des use-cases métiers trop sensibles sur des outils externes (comme des dépendances) pour éviter de mettre en péril le projet (une lib peut avoir des bugs, il vaut mieux se sécuriser en recodant certaines parties)
Refactoring et affinage du modèle en continu (c’est ce que veut DDD dans tous les cas)
Si c’est le coeur du système alors on choisit de séparer les parties génériques qui le compose au maximum pour n’en retenir que le coeur
Une fois le coeur délimité, on peut commencer à réfléchir de déléguer ou non le domaine générique à une autre entité (un prestataire, une solution open-source existante, une lib…) ou le faire de notre côté
Bubble Context (Bulle de Contexte) & Anti-Corrumption Layer (Couche d’Anticorruption)
Grâce au Domain-Driven Design, on vient d’aborder des notions très intéressantes pour mieux comprendre le métier, mais aussi pour structurer notre code.
Ces patterns stratégiques nous permettent de mieux imaginer notre application en amont pour l'implémenter plus facilement après, grâce aux patterns tactiques.
C’est génial, mais pour autant on n’aura pas encore discuté d’un point super important : Le code legacy.
DDD avec ses patterns, peut tout à fait s’implémenter sur ton projet en cours.
Mais aussi sur un vieux projet avec du code legacy dégueu…
Mais alors, pour implémenter DDD, on fait quoi ?
Faut-il refactorer ?
Faut-il tout refaire ?
Heureusement, des patterns existent pour nous permettre d’utiliser DDD sans devoir refaire notre application, ouf.
Couche Anti-Corruption et Bulle de Contexte
A priori, l’idée est simple :
On utilise un pattern nommé Anti-Corrumption Layer (ACL) afin de communiquer avec le legacy sans tout défoncer.
On va partir du principe que l’on doit rajouter une nouvelle fonctionnalité sur du code legacy.
Dans tous les cas, on va devoir créer du nouveau code et jouer avec l’ancien.
Mieux encore, grâce au pattern d’anti-corrumption, on va aussi pouvoir dialoguer avec un autre contexte borné ou une API externe.
L’idée c’est de ne pas compromettre le nouveau code que l’on va créer avec du code ancien ou celui d’un autre contexte.
Comment implémenter le pattern ACL dans un Bubble Context ? 👇
Il faut traiter le code legacy, un autre contexte ou de la donnée externe (comme provenant d’une API) comme un élément externe à notre contexte actuel.
C'est très important pour éviter que le code du domaine actuel se retrouve pollué par ses interactions.
Autrement dit, le code de notre contexte (qui est drivé par notre domaine) ne doit pas être influencé par quoique ce soit.
Ce qui est malheureusement souvent le cas dans nos applications, notamment lorsqu’il y a besoin d’appels APIs externes…
Inventé par Alberto Brandolini, c’est une méthode qui consiste à réunir toutes les équipes pour définir le flow de l’application.
Ça crée un sacré bordel dans la salle de réunion, mais c'est quelque chose de très efficace pour que tout le monde puisse s'accorder sur ce qui est voulu et les termes associés.
Durant cette technique d’interview, tout le monde est présent (équipe technique et métier, le PO, les services externes concernés ou leurs représentants…).
https://www.eventstorming.com/book/
TOUT LE MONDE.
Le but c'est d'initier une communication, c'est une belle excuse pour se retrouver avec le métier dans la même pièce.
On pourra ainsi :
Faire valider le flow de l’application par tous les acteurs présents ;
Trouver les hotspots (les points chauds, les éléments complexes) avant de se les prendre dans la tronche au moment de coder ;
Avoir une vue d’ensemble cohérente de ce qu’attend le métier ;
S’accorder sur les termes à utiliser et les différents évènements liés entre eux ;
Cartographier la connaissance métier (tout le monde en profite).
Comment mettre en place un Event Storming ? 👇
Ce pourrait être un article à lui tout seul tant le sujet est vaste et intéressant !
Mais comme j’aimerais prendre le temps de détailler d’autres patterns stratégiques de DDD, on va rapidement passer dessus.
Le but de l’Event Storming, c’est de définir l’application à développer en termes d’évènements (qu’est-ce qu’il se passe ?).
Tout le monde place des stickers sur un tableau dont l’abscisse « x » est le temps
Chaque couleur représente un contexte
Tous les stickers indiquent une action au passé « un élément a été ajouté au panier »
C’est un évènement métier qui compte pour les responsables du métier.
Petit à petit, on déduplique, on s’accorde sur les mots, on s’ajuste
À la fin, on ajoute d’autres stickers pour cibler les hotspots, les services externes, les points de désaccord.
Il ne reste plus qu’à modéliser les interactions entre les différents services
On challenge tous les évènements : Qu’est-ce passe-t-il si jamais l’event PaymentReceived ne passe pas ?
Se concentrer sur les cas nominaux (notre core domain), si l’arbre devient trop grand on en fera un nouveau
Si cela t’intéresse voici une vidéo qui aborde le sujet super bien :
Tous les acteurs doivent se rassembler autour de la table, PO, Business, Développeurs… Ou a minima 3 amis
Pour qu’une User Story soit correctement décrite, elle doit être compréhensible par TOUS les acteurs du projet.
De cette manière, on peut s’assurer qu’elle a bien été comprise par TOUT le monde et qu’elle correspond exactement à ce que le métier veut
On décrit l’user-story à la manière du business, potentiellement en s’aidant du Given, When, Then
Plus il y a d’exemples, mieux c’est, alors challengeons les équipes !
Se servir de Gherkin pour traduire a posteriori les use-cases, une fois que tout le monde les a validés
Coupler ces use-cases à des tests unitaires (ou d’intégration si besoin) pour créer une documentation vivante
Le code Gherkin dans le code devient désormais la base métier (et plus le ticket initialement créé pour ça)
Patterns tactiques / techniques de DDD
Des patterns stratégiques comme des patterns tactiques, il en existe d’autres que ceux que je présente dans cet article.
(D’ailleurs ces patterns, DDD ne les a pas tous inventés)
Je vais essayer de te présenter ici les patterns techniques les plus connus utilisés par le Domain-Driven Design.
En gardant à l'esprit que ce qui fait l'âme d'un software craftsman, c'est de savoir utiliser le bon outil au bon moment pour un problème donné.
Sachant qu’il n’y a jamais qu’une solution disponible !
Le but de ces design patterns techniques, c’est de pouvoir implémenter les patterns stratégiques de DDD plus facilement.
On parlera dans la section suivante de comment tu peux intégrer DDD dans tes projets et comment coder de manière orientée domaine.
Les patterns tactiques du Domain-Driven Design (tirés du livre « DDD Vite Fait »)
POO ou la Programmation Orientée Objet
Petite exception avant de commencer, la POO.
La programmation orientée objet convient bien à l’implémentation d’un modèle de donnée car elle permet de modéliser les objets du domaine et leurs relations.
La programmation procédurale elle, s’appuie plutôt sur des structures de données. 👇
L'avantage de la programmation orientée objet est qu'elle permet à une classe et son instance de se gérer elle-même (de changer son état) et de définir le comportement de l'objet (le rendant ainsi non-anémique).
Pour rappel, un modèle anémique est un modèle qui ne fait rien par lui-même, il n’a pas de comportement propre (souvent c’est une classe avec de simples attributs et des getters/setters).
Pour en revenir aux structures de données, on ne peut pas refléter de comportement métier avec elles.
C’est pourquoi la programmation procédurale n’est pas vraiment recommandée en DDD.
Concepts de la POO
Comment tirer parti des objets le plus possible ? 👇
Ici, on voit que le modèle gère lui-même son état, il est donc l’inverse d’anémique.
Dans la mesure du possible, il faut que ton objet :
Avale la complexité du domaine dans des classes métiers
Supprime la complexité accidentelle (accès concurrent…)
Simplifie le raisonnement en déléguant la logique, elle est encapsulée directement dans des méthodes
Soit hyper testable et TDD friendly
Introduise la graine du domaine dans le code, on lui donne du sens
Colle la structure de données au plus proche du métier
Value Object / Value Type (Objet-Valeur)
Value Object (VO) est un moyen d’implémenter un concept de valeur dans un langage de programmation.
Les Value Objects simplifient le design, sont partageables, immuables, copiables, serializables...
Et chacun de ces objets valeurs en vaut un autre.
Par exemple : un genre, une devise, une adresse ; tout ceci peut être partageable, ça n’a pas d’existence propre.
Tout billet de 10€ vaut n'importe quel autre billet de 10€.
C’est donc par essence un Value Object (VO).
Les avantages d’un objet-valeur
Découper les entités plus proprement
Dégager de la complexité métier dans une classe dédiée
Exprimer le domaine métier plus facilement
Garder la complexité d’un objet à l’intérieur de ce dernier
Ils sont très intéressants à tous les niveaux, personnellement je les utilise le plus possible !
Immutable (pas de setter – tout se fait dans le constructeur)
Riche en logique métier : on crée les fonctions du VO en accord notre comportement métier
Complètement défini par l’ensemble de ses attributs (si on concatène l’ensemble des champs on doit pouvoir la comparer avec une autre instance) – égalité forte, unicité forte
Entity (Entité)
On vient de voir qu’un Value Type (ou Value Object) pouvait s’échanger avec n’importe quel autre.
En effet une adresse peut être partagée par plusieurs personnes, aucun problème avec ça !
Une entité en revanche, c'est unique, traçable, shardable.
Même si tous les attributs de 2 entités sont les mêmes, elles seront tout de même différentes.
Une personne physique, un animal de compagnie, une facture…
Ces éléments ne peuvent pas être interchangeables entre eux.
Même si une personne a le même nom, prénom, date de naissance, taille, poids… Qu’une autre, pour autant ce seront 2 personnes distinctes.
Les entités permettent de créer de l'identité, quelque chose d'unique, distinguable parmi d'autres éléments - c'est pourquoi elles ont souvent un ID unique.
Second point, les attributs d’une entité sont amenées à évoluer.
L’âge, le poids, la couleur des cheveux, le QI…
Une entité est mutable par principe, on peut changer son état !
Or, un objet valeur lui reste immutable (10€ c’est 10€, inflation ou pas).
Comme les entités ne sont pas thread-safe (deux threads ne peuvent pas modifier la même entité en même temps), on préféra utiliser des VOs lorsque c’est possible.
Distinguer une entité d’un value object ?
Si je te dis de modéliser une lampe.
C’est une entité ou un value object ?
Prends le temps de réfléchir, c’est une vraie question 😈
Par principe :
Une lampe neuve en vaut n’importe quelle autre chez IKEA, si elles ont les mêmes caractéristiques, le même prix : c’est un objet valeur.
Une lampe d’antiquité ou d’occasion a possiblement des caractéristiques différentes ou un état général qui diffère malgré le fait que ce soit le même modèle : c’est une entité.
Moralité ?
Tout dépend de ton métier (c’est souvent le cas avec le Domain-Driven Design !).
C'est le modèle métier qui va driver le modèle dans ton code.
Littéralement.
Par conséquent c’est aussi lui qui décide du type à choisir.
DDD va suffisamment loin au point de faire correspondre des éléments métiers directement dans le code de l’application.
Alors profites-en et ne te bats pas contre le métier, c’est lui qui a raison s’il te dit qu’une lampe est une entité !
Comment créer une entité ? 👇
Ne pas la confondre avec une entité au sens ORM comme avec Doctrine, ça n’a rien à voir 🙂
Généralement une entité a un identifiant unique (uuid, id auto-incrémenté, numéro de sécurité sociale, numéro de compte bancaire…)
Une entité est mutable, son état change d’un moment à l’autre, elle a son propre cycle de vie
On essayera de créer des fonctions métiers dans cet objet plutôt que de créer un modèle anémique (pareil que pour le Value-Object)
Ce ne sont pas des DTOs avec des primitives, ils sont une réelle représentation métier avec leur propre cycle de vie
Fail Fast : On arrête tout dès qu’il y a un problème (souvent on lève une exception, on fait une assertion)
Aggregate Roots (Agrégats racine)
L’aggregate root ou agrégat racine est une unité de confiance pour le développeur.
C’est une entité dont le but est de protéger les « sous-entités » qu’elle contient, et notamment les règles de gestion qui doivent gérer les différents états de l’entité en question.
L’aggregate root représente un concept métier que tu peux représenter à l’aide de classes.
Les agrégats m’ont de suite fait peur lorsque j’ai commencé à m’intéresser à DDD, mais fonctionnellement c’est assez simple.
Un agrégat racine part du principe que seule une entité de notre module pourra sortir de celui-ci et discuter avec les autres, c'est notre point d'entrée à l'utilisation des objets du domaine dans le module.
Un agrégat racine en DDD ne gère qu’une seule problématique de manière transactionnelle.
L’avantage de ne pas exposer les relations de l’entité est que la gestion du comportement reste dans l’agrégat racine, c’est lui qui gère ses « enfants » et personne d’autre.
Les invariants
Les invariants sont ces règles qui doivent être maintenues à chaque fois que les données changent.
Par exemple dans le cas d’une édition d’une facture, tu ne dois pas être capable de changer le numéro de facture généré.
De la même manière, tu ne peux pas mettre une TVA à 0% si tu ne spécifies pas une mention pour cela.
Ces règles de gestion, ce sont des invariants.
DDD, grâce aux agrégats racines nous permet de protéger ces invariants en les cachant aux yeux des services externes.
Voici un exemple de règle simple pour bien comprendre : On ne peut pas rajouter de nouvelles lignes de facturation si les premières n’ont pas déjà été remplies.
Logique.
En appelant la méthode Bill.addLine(), on s’assure que cette responsabilité reste au sein de l’agrégat racine et n’est pas déléguée à un service externe.
L’objet s’autovalide et l’invariant est protégé : personne ne peut ajouter de lignes sans en avoir rempli au préalable.
Ici on voit que tous les objets du module ne sont pas accessibles de l’extérieur, et tant mieux que ça n’aurait pas de sens !
Dans cet exemple, on a encapsulé la complexité et notre règle métier dans l’agrégat.
Si nous avions séparé les actions, rien n’aurait pu nous empêcher d’écrire ce (mauvais) code :
Le changement d’état est uniquement géré par l’agrégat racine
Comment créer un aggregat root ? 👇
Clusturiser les entités et les objet-valeurs dans un module avec ses frontières
Choisir ensuite l’entité qui sera la racine de ton agrégat : c’est ton aggregat root
C’est elle qui sera responsable de communiquer à l’extérieur de ton module, c’est elle qui est exposée
Elle discute aussi avec les membres de son module, de son domaine
Les objets du module sont protégés vis-à-vis de l’extérieur, ils ne sont pas exposés (private)
Les opérations sur les objets du domaine sont effectuées avec une seule opération
Les changements d’états des enfants sont uniquement gérés par l’AR
Un seul agrégat par module permet de bien découper son code
Un agrégat par donnée qu’on a besoin de charger (on ne factorise pas !)
Services
Certaines actions ou comportement métier n’appartiennent pas forcément au domaine.
Les services représentent un comportement important de notre application, mais comme on ne peut les mettre dans aucune case, ils se retrouvent "services".
Généralement, pour les services qui effectuent des actions, on n’a pas besoin de new (outre dépendances).
Donc : Les services s’injectent, sont remotables (on les appelle) ne se déplacent pas et…
Font des actions avec des objets.
Leur seul but est de fournir une fonctionnalité (souvent au domaine).
Par exemple, transférer de l’argent d’un compte à un autre.
Cette fonctionnalité ne peut pas se retrouver dans le compte qui débite ni celui qui crédite, par essence l’action doit se retrouver dans un service tiers.
Aussi simple que cela.
Pour autant il faut privilégier le changement d’état des objets dans les objets eux-mêmes lorsque c’est possible !
Comment créer un service ? 👇
Un service n’a pas d’état interne, il ne fait que gérer des objets qui peuvent en avoir
Il gère l’interaction entre plusieurs objets
Un service se crée lorsque la responsabilité d’une action ne peut pas être conférée qu’à une seule classe
Il fournit une fonctionnalité au domaine, fonctionnalité qui ne peut pas se retrouver dans un VO ou une entité
Un service ne remplace pas une action qu’est censée faire un objet
Permet d’éviter de coupler trop fortement les objets entre eux
On peut séparer davantage de responsabilité avec un service
On peut manipuler plusieurs objets du domaine lié (en même temps)
Distinguer les services par couches
3 types de services peuvent être créés si tu tiens compte de l’architecture en couches que l’on verra un peu après.
Pour les distinguer avec un exemple simple, partons de la mise à jour d’une fiche de préférence utilisateur.
Application Services : Envoient le formulaire à la vue et se charge de récupérer les informations.
Domain Services : Contienent le code métier, ils vérifient les données reçues, appliquent les règles de gestion…
Infrastructure Services : Récupèrent les préférences et les renvoient à nouveau en base de données.
3 types de services pour 3 actions bien différentes.
Repository (Entrepôts)
Les repositories sont un concept très utilisé à l’heure actuelle.
Tous les frameworks modernes de développement web les implémentent.
Avec ce Design Pattern Repository, on se sert d'une interface pour accéder aux données, peu importe où elles se trouvent.
C’est un gros avantage, car le métier se fiche complètement d’où se trouve la donnée à l’instant T (API, Redis, Base de données, fichiers sur le disque…).
Grâce au Repository, on est capable de ne pas tenir compte de l’accès à la donnée depuis notre domaine.
Le Domain-Driven Design souhaite isoler le domaine et l’architecture.
On est à l’intérieur de notre domaine métier, le but n’est pas de savoir comment les données se stockent mais plutôt si elles se sont bien stockées.
La persistance-ignorance c'est très bien pour le core domain, car ça ne concerne pas le modèle métier.
Aussi, si jamais il y a besoin de changer de système de données, on a plus qu’à plugger l’interface repository et ça y est, on est passé de MySQL à PostgreSQL.
Parfois certains objets sont plutôt complexes à créer et nécessitent un peu plus de traitement qu’un simple new devant la classe à instancier.
On utilise pour cela le pattern builder.
Un builder ou constructeur est un service qui permet d'instancier des objets qui peuvent nécessiter d'être construits avec certaines dépendances ou certains paramètres qui peuvent sortir de notre Bounded Context, c'est une usine de création d'objets.
Une factory elle, a la responsabilité de créer un objet en fonction de son entrée.
Le plus souvent c’est une classe qui permettra de :
Transformer un objet métier ;
Construire un modèle en fonction de la persistance en base de données ;
Construire un objet depuis une couche externe (comme un appel API).
Comment créer un factory ? 👇
J’utilise une interface et je l’implémente par class ;
Chaque méthode définie une entrée brute et une sortie « construite » ;
Elle me permet d’avoir une idée claire des données en entrées et en sorties.
Voici un exemple simple de factory avec un builder qui permet de :
Valider la création de notre objet par une API externe (type Google Maps).
Gérer la possibilité qu’un pays n’autorise pas le dépôt d’une annonce d’un montant supérieur à x euro.
Vérifier l’existence d’un titre similaire en base de données.
Comment créer un builder ? 👇
Dès qu’un objet a besoin d’être composé, calculé ou vérifié à sa création
Si on a besoin de services externes pour le créer ou le valider
Dans le cas où sa construction est complexe
Merci pour les précisions de « Max » et « Topic » en commentaire. 🙏
DDD Architecture
Choisir la bonne architecture est TOUJOURS difficile.
En Domain-Driven Design, on aime beaucoup les architectures souples et malléables, que l’on peut changer facilement en termes de structure pour pouvoir les faire évoluer plus facilement si besoin.
Choisir son architecture, c’est toujours une histoire d’optimisation des coûts futurs.
Il faut anticiper les changements de demain pour pouvoir être réactif.
Par définition, on dit que tous les modèles architecturaux sont faux, que l’on ne fait jamais que des compromis pour faire « au mieux »…
Il n’y a donc pas qu’une manière de faire des architectures métiers.
Mais bien souvent quand on parle DDD et architecture, on se retrouve vite avec des termes comme :
Architecture hexagonale
Onion architecture
Architecture en oignon
Port-Adapter architecture
Clean Architecture
Screaming Architecture
Architecture en couches
Il existe quelques nuances entre elles mais l’objectif reste somme toute le même !
Isoler le code du domaine et rendre l’application la plus indépendante possible entre chaque couche 🙂
Éric Evans propose un nouveau modèle pour architecturer une application centrée sur le domaine.
L’enjeu avec le Domain-Driven Design, c’est de faire correspondre l’architecture et le code au domaine métier.
Dans le meilleur des mondes on essayera de rendre le projet le plus parlant possible, rien qu'avec sa structure de dossier.
Ne serait-ce que pour que les futurs développeurs qui rentrent sur le projet puissent le comprendre plus facilement.
Généralement, une application « classique » ressemble souvent à son starter.
Par exemple si tu choisis de démarrer un nouveau projet Symfony, il y a de fortes chances pour que tu te retrouves avec la structure qui t’a été fournie par Symfony :
Architecture Symfony fournie par défaut
Cette architecture n’est pas mauvaise en soi, mais elle n’est pas adaptée pour des projets de grande envergure.
Pourquoi ?
Car avoir une structure de dossiers orientée « type de fichiers » ne te permettra pas de faire évoluer ton application au-delà d’un certain seuil.
Ici par exemple, plus ton appli va grossir et plus ton dossier « components » va se remplir jusqu’à atteindre un stade ou plus rien n’est maintenable…
Il existe bien évidemment des techniques pour faire différemment, mais tu vois l’idée.
C’est là que l’architecture en couches intervient !
Architecture en couches : comment ça fonctionne ?
Pour mieux comprendre, voici un exemple tiré du livre « DDD Quickly » dont je parle dans la section « Livres » de l’article.
L’idée, c’est de décomposer son application en couches.
Architecture en couches proposées par Eric Evans
User Interface (Interface utilisateur) : Présentation des données à l’utilisateur, en théorie, elle ne fait « que » ça ;
Application (Services applicatifs) : Pas de logique métier, elle sert de coordination avec les autres modules de l’application (c’est là que sont tes contrôleurs, tes endpoints d’API…).
Domain (Domaine) : Représente les objets du domaine avec toutes les règles métiers associées (c’est le cœur de l’application, ou presque) ;
Infrastructure : Permet d’accéder aux données des autres couches et de fait, s’occupe de la persistance.
Règle : Chaque couche ne peut interagir qu’avec elle-même ou une couche plus basse.
Cette séparation des préoccupations permet d’éviter de fortement coupler les parties qui n’ont rien à voir entre elles.
Très souvent, le code métier se retrouve dépendant d'un accès à une base de données.
On essaye donc ici au maximum de séparer les couches et les actions entre elles…
De fait, les couches sont interchangeables facilement !
Plus envie de Doctrine, on passe à Eloquent ? (Ce sont des ORMs PHP)
C’est chiant mais faisable, car on n’aura que la partie « infrastructure » à modifier et pas le reste de l’application.
Merci le design pattern repository.
Le code de l’infrastructure ne doit pas être rattaché à la logique métier…
La valeur ajoutée de notre code reste dans la partie "Domain".
Tu veux passer de Symfony à Laravel ? Tu devrais être capable de récupérer 100% du code PHP provenant du domaine.
Car ton code métier n’est pas censé être couplé à une techno (ou à une autre couche métier).
DDD veut nous orienter vers ça, vers du code avec de la vraie valeur ajoutée qui n’a pas besoin d’être refait tous les 5 ans…
Comment gérer les dépendances entre les couches ?
C’est la partie la plus complexe dans nos applications.
Gérer les dépendances, quel service a la responsabilité de quoi, jusqu’où doit aller le périmètre d’un module, d’un contexte…
C'est ça qui fait que nous sommes de vrais développeurs et pas simplement des "pisseurs de code".
La Clean Architecture nous incite à ne PAS créer de dépendances entre les couches.
Pourquoi ?
Car si tu changes un truc à droite…
Obligatoirement, ce sera répercuté à gauche.
Le Domain-Driven Design souhaite que tout ne soit pas planté à cause de dépendances cachées.
Pourtant les dépendances sont nécessaires sinon nos modules resteraient entre eux, sans relation, sans rien faire d’autre que leur propre code.
Comment faire alors ?
Le pattern « port-adapter »
L’architecture hexagonale ou l’architecture en oignon nous incitent à utiliser des adapteurs pour communiquer avec les autres parties de notre application.
Prenons un exemple simple, à l’enregistrement d’un utilisateur tu as besoin de plusieurs choses :
Couche UI : Récupérer les données du formulaire sur le front
Couche Application : Poster le formulaire sur une route API via un Contrôleur
Couche Application : Valider les entrées du formulaire
Couche Domaine : Construire notre objet à sauvegarder
Couche Architecture : Persister l’utilisateur en base de données
Couche Domaine : Générer un lien de confirmation
Couche Architecture : Envoyer un mail pour lui demander de confirmer son compte
Couche Application : Afficher un message de retour à l’utilisateur pour lui dire d’aller vérifier sa boîte mail
Couche UI : Informer l’utilisateur que son compte est en attente de confirmation
Là de l’interaction entre les couches, tu en as un paquet…
Or, chacune d’elles doit être indépendante, c’est une règle que l’on ne peut pas et que l’on ne veut pas violer.
Ce pattern est assez long à expliquer alors je t’invite à lire l’article ci-dessus qui explique cela beaucoup mieux que moi.
Inversion de dépendance
Il faut bien séparer la logique métier et la logique du code, de l’infrastructure.
Mais il faut aussi séparer les interactions entre les services internes (domaine : logique métier donc) et les services externes (API tierce, base de données, e-mails…).
Et comment on rend des éléments indépendants ?
Avec le 5 ème principe SOLID sur l’inversion de dépendances !
L’avantage de l’interface est de pouvoir changer de repo quand on veut, si jamais les utilisateurs se retrouvent en LDAP ou dans un fichier CSV, on s’en fiche !
Alors oui, ça va créer beaucoup d’interfaces sur les parties où les couches ont besoin d’interactions…
Mais la contrepartie de ça c’est que chaque couche devient INDÉPENDANTE !
Cette vidéo est sûrement la meilleure que j’ai vue sur la Clean Architecture en français, elle vaut le coup si tu t’y intéresses.
Si comme moi tu débutes avec tout ça, je te conseille de regarder des vidéos ou des dépôts GitHub dans ton langage et ta techno pour t’inspirer de ce qui existe déjà.
Car c’est très difficile d’architecturer une application.
D’où le fait que le Domain-Driven Design soit à destination des développeurs seniors.
Il est très important que l’architecture choisie soit répercutée par l’ensemble des développeurs dans le projet.
Comme la structure est assez différente de ce qui est généralement choisi (une bonne vieille structure MVC), il faut veiller à ce que la création des dossiers et des fichiers reste cohérente avec le reste de l’application.
Voici quelques exemples d’applications en DDD que j’ai trouvé sympa.
Du Domain-Driven-Design avec API Platform – Mathias ARLAUD Robin CHALAS – Forum PHP 2021
Du DDD dans mon legacy ! live coding (T. Pierrain, B. Boucard, J. Grodziski)
Exemples de projets DDD
Il est assez difficile de trouver des dépôts GitHub ouverts (publiques) avec du code bien fait en DDD.
Comme le Domain-Driven Design est fortement couplé au métier, on ne peut généralement pas se permettre de le rendre visible par tous.
Le Core Domain est le business de l’entreprise, on ne peut pas se permettre de le voir copier par la concurrence.
Pour autant j’ai trouvé quelques dépôts sympas avec des exemples de code DDD :
Quand il y a trop de dépendances ou trop de fonctionnalités à exercer par une même application ou encore trop de liens entre les contextes…
La gestion des sétat par évènements peut être d'un grand secours.
Je ne vais pas trop m’attarder sur ce point car c’est un ÉNORME morceau.
À la place je vais plutôt citer quelques articles que j’ai bien aimés et qui permettent d’expliquer :
Le « Command Pattern » : Un émetteur envoie des commandes préconstruites à un receveur qui se chargera d’appliquer du code métier ;
L’Event Source (ES) : Permet de tracer les changements d’une application en stockant les évènements liés aux changements d’états plutôt que les états eux-mêmes ;
Le projet peut déjà être existant ou démarrer de 0.
Dans les 2 cas tu peux tirer avantage de l’utilisation du Domain-Driven Design !
Ça, c’est la bonne nouvelle.
Pour chaque bon design il doit en avoir eu avant au moins 3 mauvais.
Éric Evans
Ça, c’est la mauvaise nouvelle.
Il faut laisser le temps aux équipes de monter en compétences sur DDD et sur le métier qu’elles doivent implémenter.
Les deux se faisant en parallèle, les premières implémentations ne pourront pas être réussies à 100%…
Mais ce n’est pas grave, car dans tous les cas on doit y passer.
Comme on va se planter, commençons petit…
(Et si tu peux, fais-toi encadrer par un dev senior.)
Sur quelle base de code commencer DDD ?
Le Domain Driven Design se vit en codant, tu vas donc devoir te trouver une base de code sur lequel t’amuser.
A priori comme tu as 80% de chance de te planter, il vaut mieux jouer doucement avec le concept métier dans un premier temps.
Sur une application existante
Prendre un concept chiant à maintenir ou bugué
Choisir un concept métier important qui a besoin d’être revu
Définir les parties du code qui changent le plus souvent, car DDD tire sa force du fait que la maintenance est réduite
Forker le dépôt et s’amuser à refactorer certaines parties en workshop
Training day sur un nouveau concept
Sur une nouvelle application
Projet perso même si ça n’a pas trop de sens (les projets simples / sans contrainte business fortes n’ont pas besoin de DDD)
Démarrer un projet avec DDD ne veut pas dire d’utiliser tous les outils que l’on a vus, tu peux commencer petit
Partager sa vision du modèle au domaine (n°1)
La toute première étape, c’est de comprendre le métier que l’on essaye de retranscrire en code.
C’est indispensable au bon fonctionnement du projet.
Ce processus d’ingestion de la modélisation métier s’appelle : Knowledge Crunching.
C'est à ce moment précis que l'on définit l'Ubiquitous Language et que les parties prenantes (développeurs, chef de projets etc) s'approprient le besoin métier... Comme si c'était le leur.
C’est vraiment LA puissance du Domain Driven Design !
Sur les prochaines réunions, essaye de te mettre à la place de ton client pour le challenger sur ses propositions, sur ses besoins.
Sois force de proposition, apporte-lui tes idées, soulève les zones d’ombre, partage ce que tu penses, mets en avant des solutions techniques existantes qui peuvent faire avancer le projet…
L’implication personnelle est la clef pour importer le DDD dans ses projets.
Comprendre les enjeux de son client et l’aider à y parvenir outre le fait de coder une application, c’est ça être un vrai développeur.
Ce sentiment d’avoir accompli quelque chose en plus ne te quittera pas non plus.
Comment procéder ? 👇
Être (désormais) présent auprès des spécialistes métiers ;
S’accorder sur un langage commun, respécifier les termes si besoin ;
Ingestion de la modélisation métier : construire le modèle de données en fonction de la structure imaginée par le métier ;
Documentation sur ce qui a été compris par les équipes techniques (BDD, Tickets, Doc partagé…) ;
Validation de ce qui a été compris à l’aide des user stories / use-cases ;
Feedbacks et retours de l’existant avec le métier (technique ou fonctionnel).
(On boucle là-dessus jusqu’à ce que ce soit bon !)
Pour les projets déjà existants, on peut tout à faire le faire sur de nouvelles fonctionnalités, un nouveau module, les nouvelles réunions…
Matcher le domaine métier dans le code (n°2)
Une fois le modèle fonctionnel clairement établi, il faut imaginer l’implémenter dans le code.
L’étape de la modélisation est donc super importante !
Dans l'approche DDD on peut / doit changer de modèle si le besoin s'en fait sentir, si le besoin initial a évolué, si le besoin a mal été retranscrit...
L’objectif est d’avoir la retranscription la plus simple et la plus logique entre un besoin métier donné par ton client et ton code.
Mais attention, car il existe souvent une grosse différence entre :
Le modèle métier imaginé par les équipes métiers ;
Le modèle métier implémenté dans le code par les développeurs.
Et là-dessus, le Domain-Driven Design te met en garde.
« C’était plus simple de relier ces deux objets finalement ».
« On a mergé les attributs de ces 2 classes pour factoriser un peu ».
« Finalement on a séparé cette entité en 5 autres entités distinctes pour garder un historique ».
Des développeurs qui prennent des libertés sur le modèle métier.
Tous ces choix techniques peuvent se discuter mais…
Ils doivent être discutés avec l’ensemble de l’équipe.
C’est ça, la règle.
Il faut en discuter tous ensemble 🙂
C’est ce qui est dans la tête du développeur qui va partir en production, pas ce que l’expert du métier souhaite / les connaissances du métier.
Alberto BRANDOLINI
C’est pour cela qu’avec DDD, les développeurs doivent être conviés aux réunions.
Le risque ici, c’est qu’à force de petit changement, le modèle final diffère totalement du modèle initialement conçu qui lui, de manière certaine, répondait au besoin fonctionnel.
Dans la mesure du possible, il faut éviter de tordre le besoin fonctionnel pour le faire rentrer dans un besoin technique.
C’est plutôt l’inverse qui devrait se produire.
Comment procéder ? 👇
Schéma de données ou des interactions afin d’avoir une vision claire du modèle et des comportements (tout le monde n’est pas d’accord là-dessus mais…)
Ne pas se concentrer sur une seule technique comme UML ou le diagramme de classes
Faire un dessin à main levée, un wireframe, du texte… tout ce qui marche pour comprendre le besoin
Les enjeux techniques peuvent aussi être abordés en réunion si c’est pertinent
Ne pas hésiter à utiliser les patterns stratégiques de DDD : Carte de contexte, Distillation du domaine, Bull de context, Contexté Borné…
Les scénarios et BDD sont tes amis, il faut créer un maximum de usecases que tu pourras retranscrire dans le code
Utiliser des modules logiques pour organiser les besoins clients, penser architecture assez rapidement grâce aux Bounded Contexts
Conception dirigée par le modèle (n°3)
Cette section servira de base à l’implémentation des patterns tactiques de DDD.
En effet, la conception dirigée par le modèle est au coeur de l’application des « tactical patterns ».
Ce sera également l’occasion d’y voir quelques bonnes pratiques de POO.
Objectif simple : Il faut lever les ambiguïtés du code autant que possible sur le domaine métier.
Comme nous venons d’établir le modèle par l’ensemble de l’équipe (comprendre validé par les équipes techniques ET fonctionnelles), on va pouvoir intégrer ce modèle directement dans le code.
Cependant, il faut être vigilant :
Le modèle fourni est peut-être inexact, non optimisé, interprétable, ayant trop d'éléments ou pas assez, trop de détails ou pas assez...
Plutôt que de corriger ce modèle avec ce que l’on pense être bon en tant que développeur, il faut le retravailler en amont avec les équipes métier.
https://slideplayer.fr/slide/3894312/
Tout changement du modèle imaginé par le métier doit leur être rapporté.
On peut alors revoir le modèle, les besoins, les enjeux.
Si on ne le fait pas, le modèle non validé par le métier partira en production…
Alors que justement, ces mêmes membres du métier penseront qu’il reflète leurs idées.
Leur vision n’aura pas été implémentée, début de soucis en cours…
Domain Modeling : Le modèle d’analyse / modélisation dans le code
C’est ce qu’a compris le développeur qui partira en production.
Pas la vision du métier.
Il ne faut SURTOUT PAS dissocier l’analyse du besoin et l’implémentation dans le code mais le faire conjointement, de manière efficace.
Le développeur pourra pointer du doigt les limites techniques d’une idée, d’une implémentation, d’un souhait ou d’un besoin.
Si on sépare ces deux étapes (création du modèle côté métier et implémentation côté développeur), des informations risquent de se perdre.
Comment procéder ? 👇
Microsoft a fait un bel article sur le sujet et ils préconisent de fonctionner ainsi.
Une fois le modèle établi plus haut avec les équipes, on commence à l’architecturer dans notre code
On crée les modules, les Bounded Contexts, les agrégats, les Value Objects, les entités, ACL…
On redéfinit les interactions entre les contextes afin d’identifier rapidement de nouveaux problèmes (Context Map)
Si des problèmes existent on les remonte au métier afin de challenger le modèle déjà établi
Les développeurs pourront pointer les limitations techniques
L’équipe métier pourra certifier que cela remplit toujours leurs besoins
On ré-implémente le modèle dans le code
Il faut itérer comme cela jusqu’à ce que cela marche
Toujours remettre en question le modèle métier si jamais une limitation technique est trouvée en cours de route
Une fois les contextes clairement établis on peut se les dispatcher dans l’équipe
Comment coder en DDD (n°4)
DDD c’est difficile et il n’y a pas qu’une manière de faire.
Ce que je décris plus haut, c’est comment moi je me suis mis dedans.
La manière de faire n’est peut-être pas idéale mais comme il est très difficile de trouver par où commencer…
Je me suis fait ma propre DDD roadmap.
On sera tous d'accord pour dire que le Domain Driven Design nous permet d'apprendre et de monter en compétence sur le domaine métier que l'on souhaite coder.
Que le but est de tacler la complexité.
Le code doit donc refléter le métier et être compréhensible, lisible par quelqu’un de non technique…
Alors bien sûr c’est à relativiser, mais dans l’idée tout le monde est capable de lire ça :
Code intelligible (DDD compliant)
C’est de suite beaucoup plus intelligible que :
Code non intelligible (pas DDD compliant)
Il faut tendre vers du code métier et non du code technique.
Toujours transcrire l'intention métier dans le code.
Pour aller encore plus loin, le métier devrait comprendre tous les noms de fichiers sur l’arborescence de l’IDE…
Abuser des namespaces
Les espaces de noms permettent de séparer les objets en fonction des modules / contextes bornés.
C’est génial, car on est capable de déterminer l’appartenance d’un objet à un contexte précis juste avec l’instance donnée…
\App\Domaine\Livre\Auteur
\App\Domaine\Blog\Auteur
Ici pas besoin de faire de dessin 🙂
Monolith First
Attention à la hype des micro-services !
Faire un bon monolithe c’est déjà difficile, alors faire de bons microservices…
Un monolithe trop couplé en microservice = Monolithe distribué.
L’idée en tout cas, c’est que comme chaque module peut être packagé indépendamment, si un jour on devait en sortir un de l’application, on pourrait plutôt aisément.
Dans tous les cas, il faut privilégier le monolithe et le déporter en microservice uniquement si le besoin s’en fait sentir (en termes de complexité, de performances, de scalabilité…).
Microservice Ready
La bonne pratique est vraiment d’essayer de faire un monolithe propre, bien comme il faut.
On peut tenter l’architecture microservice lorsque la complexité devient trop grosse pour être conservée à un seul endroit.
Mais attention, il faut vraiment que la modélisation métier soit importante et complexe.
Sinon ça n’aurait pas de sens.
Architecture microservices chez Netflix : https://www.slideshare.net/JoshEvans2/mastering-chaos-a-netflix-guide-to-microservices
Séparer proprement l’application en Bounded Context peut déjà être une belle solution, ceci apportant notamment :
Une autonomie des équipes dédiées sur LEUR bounded context ;
Grâce au Context Map : on sait qui fait quoi ;
Les couches d’anticorruptions isolent les services entre eux qui RESTENT totalement indépendant ;
En cas de dépendance forte entre deux microservices il ne faut pas hésiter à les regrouper.
Isoler les règles métiers
Coder DDD c’est faire retranscrire le besoin client dans le code.
Autrement dit, les règles de gestion du métier (les invariants) se retrouvent dans une partie du code et son facilement déportables.
Elles ne sont pas couplées à la couche d’infrastructure (base de données, API externes…) et se retrouvent dans le domaine.
Make the implicit, explicite
UserService, ProfileFactory, FileModel…
Ce sont des noms techniques.
Pas des noms métiers.
Dans la mesure du possible il faut essayer de décrire au maximum les intentions métiers dans les noms de fichiers.
UserService deviennent UserRegistration et UserAuthenticator
ProfileFactory devient ProfileBuilder
FileModel devient File
Je ne pense pas avoir besoin maintenant de te dire ce que font ces fichiers, cela paraît plus facile à comprendre.
Le Domain Driven Design ici est mis en avant car nos fichiers transpirent désormais le métier.
Le but n’est pas de supprimer toute trace technique dans le nom des fichiers, mais surtout de se concentrer sur la partie métier.
Tell Don’t Ask
Ce principe souhaite que les noms soient suffisamment évocateurs pour que tu n’aies pas besoin de demander « ça fait quoi ? ».
Il faut que le code soit parlant le plus possible, pour le métier comme pour les développeurs.
Astuce : Pour éviter le code Gravity (les grosses classes tendent à être de plus en plus grosses) on peut séparer au maximum les actions métiers dans les noms de fichier.
Intention Revealing Interfaces
(Une interface ici n’est pas une interface au sens POO.)
On le sait maintenant, en DDD, l’intention est toujours clef.
Que ce soit pour nommer une classe, un fichier, une fonction…
Il faut essayer de tout nommer en gardant à l'esprit que le développeur qui ne connaît pas l'application va pouvoir comprendre l'intérêt de la fonction qu'il appelle juste avec son nom.
Imaginons que tu veuilles récupérer la liste des tee-shirts les plus achetés sur ton site.
A priori si tu as une fonction avec la signature suivante :
DDD nous incite à mieux nommer notre code, même si c’est réellement difficile.
Afin d’aider à montrer nos intentions, il ne faut pas hésiter à créer des fonctions.
Également, si jamais cela peut t’aider, pense qu’une personne du métier devrait être capable de comprendre ton appel, comme c’est le cas ici avec mon « Popular Selling : Get Top Products ».
Validation des objets
Les objets du modèle de données (entités et value objects) doivent le plus possible se valider par eux-mêmes.
Je m’explique.
Tu as 2 manières de créer des objets :
Tu fais un new Class(...params) tout ce qu’il y a de plus classique
Tu passes par une factory qui va te retourner une instance de ta classe
Le premier a une validation simple, elle peut tout à fait se retrouver dans le code même de la classe.
Le second devra être instancié via une usine donc, car sa création est plus complexe (et peut nécessiter des appels externes ou une validation un peu complexe).
Règle : Un objet dont l’état est invalide ne devrait pas être construit.
C’est aussi pour cela que les modèles anémiques sont une plaie.
Refactoring
Qu’est-ce que le refactoring ?
Le refactoring est le processus de « reconception » du code en vue de l’améliorer sans changer le comportement de l’application.
On améliore le code… Sans casser l’existant !
(J’espère que tes tests unitaires ont bien été faits, sinon ça va être plein de régressions.)
DDD sait que ton modèle va évoluer car le besoin de ton client aussi.
Il peut même changer en cours de route.
Il ne faut donc pas hésiter à modifier le modèle (en accord avec le métier) voire à supprimer du code ou des modules.
Moins il y a de code, moins il y a de bug statistiquement parlant.
https://refactoring.guru/refactoring/when
Cette étape est ultra-importante, le code doit évoluer en même temps que le métier, et à tous les niveaux.
Si jamais cela t’intéresse d’en savoir plus je t’incite à te rendre sur l’article : comment bien coder ?
Premature Abstraction
Il faut mieux abstraire après coup plutôt que trop en amont.
Cela rejoint aussi ce principe, veille à ne pas trop optimiser ton code dès le début.
Fais-le fonctionner, c’est le plus important.
On optimisera quand ça fonctionnera, comme en algorithmie !
Ne pas réinventer la roue
Le contexte distillation nous a permis d’identifier le coeur de business de notre activité.
On sait ce qui rapporte de l’argent à l’entreprise, et c’est génial.
Désormais on est capable de déporter une fonctionnalité déjà existante chez un autre prestataire (qui recoderait Google Maps plutôt que de l’utiliser ?).
Le Generic Domain peut être délégué et c’est tant mieux.
Apprendre le Domain-Driven Design
Pour apprendre le DDD, rien de mieux que la pratique !
Je te recommande donc d’ajouter un peu de Domain Driven Design petit à petit dans tes projets avec ses différents outils : Ubiquitous Langage, Value Objects, Aggregate Roots…
Personnellement, j’essaye d’applique un peu plus chaque semaine, un concept de DDD dans mon boulot.
Apprendre DDD tout d’un coup serait un trop gros morceau et il faut le temps que ça se concrétise dans ma tête.
Livres sur le DDD
Domain-Driven Design: Tackling Complexity in the Heart of Software
(de Eric Evans)
C’est sûrement « LE » livre à lire sur DDD si tu souhaites commencer quelque part.
Il est le point de départ de tout le mouvement autour du Domain-Driven Design.
Je ne l’ai pas lu car j’ai beaucoup de mal avec les bouquins techniques en anglais.
De ce que j’en ai entendu dire, il est super intéressant.
Personnellement, j’aime beaucoup l’approche DDD car elle permet une chose ultra importante :
Remettre les choses dans leur contexte.
Nous les développeurs (là je parle surtout pour moi), sommes très « technology oriented ».
Dans le sens où on maîtrise avant tout une techno et on nous demande de coder avec cette dernière…
C’est de notre faute mais pas tellement, le marché cherche avant tout un « développeur React », que tu connaisses le milieu bancaire tout le monde s’en tape.
Or DDD (et la communauté des software craftsmans en général) souhaite nous remettre dans le droit chemin :
La techno, on s'en fout.
Ce n’est qu’un outil, rien de plus.
Ce qui compte réellement c’est le métier, sa compréhension, sa reformulation dans le code, ce qui est en production, la facilité de maintenance, la satisfaction du client et des équipes sur ce qui fonctionne…
LES ATTENTES DU CLIENT COMPTENT PLUS QUE LE CODE.
DDD n’est pas une architecture, n’est pas code centric, c’est avant tout une manière de remettre le métier au coeur de nos applications. 🙂
J’ai pris des mois à écrire cet article tant le sujet est complexe…
Certaines choses sont peut-être inexactes ou ont besoin de précision ? N’hésite pas à me le dire en commentaire ! 🤗
Plus de contenu 💡
Pour lire plus de contenu similaire dans le même thématique.
J’avoue que depuis que j’ai découvert le DDD, j’applique au moins le design tactique presque partout (sauf peut-être pour un PoC).
C’est une structuration de mon code que je trouve logique et en fin de compte plus simple.
Certes, peut-être pas indispensable de créer des couches ACL avec les composants tiers et on peut faire l’impasse sur d’autres éléments qui prennent un temps qui n’est pas forcément rentable, même sur le long terme.
Évidemment, pour des projets simple, le temps passé sur du design stratégique, est plus difficile à justifier.
## Coût
Pas forcément d’accord… Du moins sur le moyen et long terme.
Mais comme tu l’indiques plus loin, c’est un investissement.
Si pour une entreprise, il n’y avait pas de ROI… alors l’investissement n’en vaut clairement pas la peine.
Non… Je pense que le facteur « coût » est réellement à relativiser.
Tout comme pour le TDD.
À long et même à moyen terme, il y aura moins de bugs ET, de part la conception en contextes découplés (si c’est bien fait), l’impact d’un bug sera en général nettement moindre.
Le code de l’application sera également plus facilement à maintenir, encore une fois, grâce au découplage. D’une part, il sera plus simple de faire la mise à jour de dépendances tiers, parce que tu auras pris soin d’ajouter une couche d’abstraction qui est précisément un ACL (donc, la plupart des correctifs se feront dans cet ACL).
D’autre part, si on parle du framework, qui fait parti de la couche infra, là aussi le découplage permet des mises-à-jour plus simples et donc plus rapide.
Facilité de mise à jour == moins de dette technique (qui elle coûte très cher à terme)
Aussi, le code sera plus facile à adapter ou à étendre pour répondre à un nouveau besoin business.
Plus de vélocité, plus de flexibilité…. plus de ROI.
Bref…
On est d’accord que quand on se lance, le développement sera plus lent et coûtera un peu plus cher…
Mais rapidement les bénéfices engendrés par le DDD surpassent ce coût additionnel (comme j’ai dit, comme pour le TDD)
## Shared Kernel
L’impression que tu simplifies un peu trop ici.
Le Shared Kernel n’est pas « juste » un value object que tu voudrais partager…
En fait pour ce genre de Value Objects (comme `EmailAddress` que tu mentionnes), j’ai tendance à les mettre dans un module `Common` puisque ce sont des composantes, comme des dépendances, que tu risques d’utiliser un peu partout.
Le Shared Kernel est un peu plus que ça. C’est un Bounded Context dont une partie des composantes (entités, value objects, comportements, fonctionnalités, etc) sont partagés avec un ou plusieurs autres Contextes.
Dans beaucoup de cas c’est pour éviter de dupliquer du code (parfois parce que c’est pas si simple que ça, par exemple si lié à du Legacy)
Exemple simple, un Context `User` qui gère aussi bien l’authentication, que ses données (mails, adresses, numéros de téléphone, date de naissance etc).
Si ton contexte `ExpeditionDeMarchandise` a besoin de l’adresse, en bon DDD, l’adresse de livraison devrait également se retrouver dans ce contexte.
Un Shared Kernel est quand `ExpeditionDeMarchandise` va directement utiliser les adresses des utilisateurs dans le contexte `User`.
Le Shared Kernel a une série d’avantages, notamment du code non dupliqué, mais engendre aussi les problèmes liés au couplage fort… Encore plus si plusieurs contextes utilisent ce Shared Kernel.
## Core – Support – Generic
Il y a quelque chose qui me dérange ici… Peut-être que c’est un peu trop résumé…
Personnellement, je préfère voir ça comme des couches dans le Business et chacun des trois est composé de différents domaines et sous-domaines qui vont, *in fine*, se décliné en Bounded Contexts.
Après, ce qui va se trouver dans ces différentes couches va énormément dépendre du contexte.
Par exemple, un soft comptable se trouvera dans presque tous les cas dans le Generic Domain… Sauf si tu es une agence de comptabilité où le logiciel, même s’il est acheté, va se trouver au centre de ton Core Domain.
En fin de compte, ce n’est pas la solution technique qui définit si un composant est core, support ou generic… C’est le métier…
Et comme tu l’as indiqué, c’est le métier qui pilote.
## POO
La programmation fonctionnelle se prête aussi très bien du DDD, d’une certaine façon, même mieux…
## Clean / Onion architecture et DDD
Note: attention que Eloquent est basé sur l’Active Record, pas Doctrine qui se base sur le Repository Pattern (je ne suis personnellement pas un grand fan du AR)
Ça a un impact considérable si on voulait switcher…
Ceci dit, il y a des devs, Laravel évidemment, qui font du DDD avec Eloquent, mais IMHO il serait nettement plus simple de basculer carrément sur du simple PDO.
## Comment gérer les dépendances entre les couches ?
Pense que tu devrais parler de la gestion d’Events (Domaines et Applicatifs) ici.
IMHO, c’est la meilleure approche pour éviter le couplage.
À ce sujet, pour PHP, jette un œil à EcoTone :
Il aide aussi énormément pour la mise en place du CQRS dont tu parles plus bas…
Tout passe par des `Bus` (`QueryBus`, `CommandBus` &, évidemment le `EventBus` pour les événements).
Moi je kiffe.
Merci pour ton commentaire super long et agréable 🙂
Je suis carrément d’accord avec toi sur le Design Tactique, car c’est avant tout du bon sens et des bonnes pratiques me concernant, je vais le préciser.
## Coût
Pour le coût, tu gagnes c’est sûr à la manière du TDD, mais je n’ai pas suffisamment d’expérience pour affirmer le contraire sur le DDD. En revanche tous les acteurs de la tech le disent, c’est plus couteux. Surtout j’imagine car les patterns stratégiques prennent beaucoup de temps, je pense que tu y gagnes sur les projets très complexes, sur les projets moyennement complexe si les méthodos de gestion de projet sont bien appliquées, a priori ça devrait aller. tu ne penses pas ?
D’autre part, si on parle du framework, qui fait parti de la couche infra, là aussi le découplage permet des mises-à-jour plus simples et donc plus rapide.
Alors moi la partie clean architecture et séparation du code métier je suis absolument convaincu. J’avoue que ça flirt bien avec le DDD et ses patterns 🙂
## Shared Kernel
Sur le Shared Kernel tu as sans doute raison, en revanche je serais curieux de voir comment tes bounded contextes interagissent entre eux ?
Pour le coup la gestion des utilisateurs je la délèguerais bien à un contexte externe en dehors de l’app, et si jamais il y avait besoin de discuter avec des classes internes, je le ferais sans doute grâce à une interface.
Si ton contexte `ExpeditionDeMarchandise` a besoin de l’adresse, en bon DDD, l’adresse de livraison devrait également se retrouver dans ce contexte.
Un Shared Kernel est quand `ExpeditionDeMarchandise` va directement utiliser les adresses des utilisateurs dans le contexte `User`.
Quand bien même l’utilisateur soit le même, j’aurais peut-être pensé à avoir 2 entités distinctes ici…
1 utilisateur qui passe 1 commande pour 1 point de livraison donné.
Afin de ne pas avoir d’info de commande dans le contexte User qui s’en balance. Je ne sais pas si c’est clair ou si je ne me suis pas égaré là 😀
## Core – Support – Generic
Tu entends quoi par couches ?
Ton exemple sur la comptabilité est super cool, je vais le faire remonter dans l’article car ça a beaucoup de sens.
## POO
Je vais creuser sur la FP, si il faut il y aura de beaux exemples !
## Clean / Onion architecture et DDD
T’as raison pour mon exemple sur le ORM, ça marche pas ! D’ailleurs j’aime pas l’AR non plus, j’en discutais au Web2Day hier avec un autre dev.
Je vais corriger ça, merci encore pour ta lecture 🙂
## Comment gérer les dépendances entre les couches ?
Cette partie était tellement longue et complexe que j’ai préféré ne pas trop l’aborder…
Mais ça va forcément fait l’objet d’un article un de ces quatre, c’est trop cool pour que je n’y aille pas 🙂
Encore MERCI pour ton commentaire super instructif !
Juste une remarque sur l’exemple donné pour les services :
« Par exemple, transférer de l’argent d’un compte à un autre.
Cette fonctionnalité ne peut pas se retrouver dans le compte qui débite ni celui qui crédite, par essence l’action doit se retrouver dans un service tiers. »
Pour moi, c’est plutôt l’exemple classique d’un aggregate « Transaction », puisqu’on voudra assurer l’intégrité du transfert.
L’utilisation d’un agrégat préserve la cohérence du système, en annulant le débit si le crédit échoue.
Article bien dense , merci pour le partage !
Petite question , mais j’ai l’impression que ce que tu décris comme Factory ressemble plus à un builder ( même si ce pattern semble très utilisé en place du Factory dans le DDD)… Et si j’ai tord , je serai ravi de le savoir 🙂
Bravo Cet article est très intéressant et surtout très instructif pour un chef de projets aussi. Cette démarche s’inscrit parfaitement dans les objectifs de la méthode de gestion de projet (méthode Prince 🤴 2 par exemple)
Excellent article qu’il me faudra relire plusieurs fois pour le contextualiser dans le vocabulaire de mon organisation et en extraire toute sa richesse.
Zoomons par exemple sur le modèle en couches, si tu le veux bien.
Ton découpage est : user interface + application + domaine + infrastructure
Dans notre langage corpo, nous découpons en : front-office (FO) + middle-office (MO) + orchestrateurs par domaine (ORK) + services élémentaires (SE) + back-office code métier et persistance (BO)
1 FO consomme 1 MO mais 1 MO peut être consommé par plusieurs FO
1 MO consomme 1 à n ORK, voire 1 à n SE directement.
1 ORK = 1 domaine, nous avons donc 1 ORK transverse. 1 ORK consomme 1 à n SE
1 SE consomme 1 BO
Dans un monde idéal, notre code métier devrait être uniquement dans les BO.
Mais dans la réalité, certaines règles métiers se trouve aussi dans le MO voire dans le FO ou l’ORK.
Exemples ?
Règles spécifiques à 1 FO d’une marque ou d’une population (parmi client final/courtier/agent/partenaireB2B…) => généralement codées dans le MO mais aussi parfois dans le FO. Cela dépend du nombre de FO connectés au MO et de la disparité des règles. C’est un de nos défauts 😉
Dans l’ORK, il peut y avoir des process métiers divergents de part l’historique des BO (le nouveau système d’assurance vie, celui d’avant, celui d’avant encore…).
Si l’urbanisation des SI était à 100% nous n’aurions pas ces verrues, mais cessions/acquisitions/rénovations etc… ne s’accompagnent pas toujours de cet effort.
Et dans la vraie vie, le nouveau système X remplace l’ancien système Y… à 80% car migrer les 20% restants vers X coûte trop cher
Au niveau de la data, les données vives du métier (les objets métiers comme proposition, contrat, prestation…) sont bien persistées dans les BO.
Mais nous avons aussi de la data dans les MO. Les paramètres applicatifs mais aussi les données de travail, celles collectées avant validation des objets métiers.
Du coup, j’ai du mal à faire matcher notre archi en couches et la tienne (surtout avec la vue Onion)
Et dans la vraie vie, le nouveau système X remplace l’ancien système Y… à 80% car migrer les 20% restants vers X coûte trop cher
T’as tout résumé…
Avant j’avais tendance à être assez extrême dans ma manière de coder et de voir l’architecture.
Désormais, je suis plutôt dans une optique de faire « au mieux en fonction des contraintes ».
Pour l’architecture hexagonal… J’ai parfois énormément de mal à dealer avec, notamment car elle rajoute une bonne couche de complexité là où certaines choses devraient être simples (notamment sur la DI).
De ce point de vue là, je t’invite à discuter avec Julien Topcu et Nicolas De Boose. J’ai beaucoup appris d’eux et je pense qu’ils auront plein de questions intelligentes à poser à tes questions 😉
Ton article est vraiment ultra-détaillé et inspirant.
J’en suis à sa 4ème lecture, mais je sens qu’il y a encore de la richesse à en extraire.
Dans mon organisation, nous nous targuons d’être DDD avec une architecture en couches.
Pourtant, certains symptômes ne font penser que tel n’est pas le cas.
J’ai donc tenté de projeter notre architecte sur le modèle que tu proposes, mais des incohérences apparaissent.
Sûrement dues à nos divergences de langage (le langage commun est déjà très difficile à fixer au sein d’une organisation, c’est encore plus compliqué entre plusieurs organisations) mais aussi par des réflexes (pavloviens ?) développés de notre côté.
Je crains d’être influencé par des biais de confirmation, car notre architecture est le résultat d’une longue réflexion, avec des fausses pistes, des remises en questions et des réorientations.
Si je t’expliquais notre architecture actuelle, serais-tu disposé à la regarder avec l’œil du candide ?
Comprendre, avec l’œil et l’esprit non pollués par nos biais ?
Soyons clairs, je n’ai pas de budget pour lancer une telle étude via un contrat formel.
J’imagine ta contribution à une grosse paire d’heures (au pire 4).
Je ne peux te promettre que de la visibilité sur Twitter et LinkedIn (oui c’est peu).
Je crains d’être influencé par des biais de confirmation, car notre architecture est le résultat d’une longue réflexion, avec des fausses pistes, des remises en questions et des réorientations.
La bonne architecture c’est celle qui correspond à tes besoins… C’est pour moi ce que le DDD essaye de transmettre, remettre le métier et ses besoins au coeur du code.
Et non pas se laisser dériver par un template ou une méthodologie rigide…
Honnêtement je ne suis vraiment pas certain de pouvoir vous aider.
Cet article est le fruit de 6 mois de recherche et je commence à peine à appréhender la chose dans sa globalité.
Bon courage pour vos recherches, et encore plus pour ton commentaire !
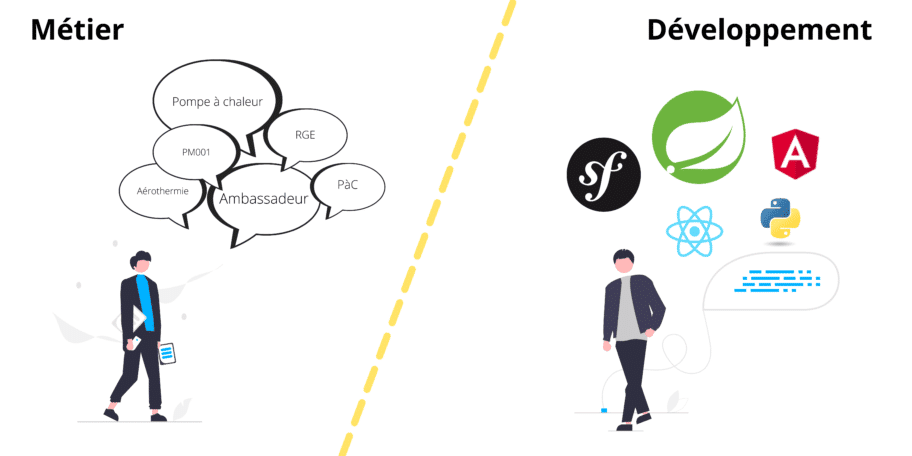
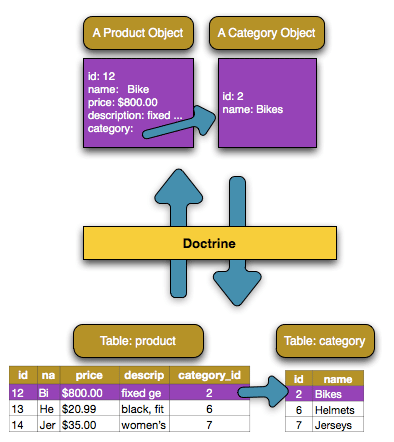
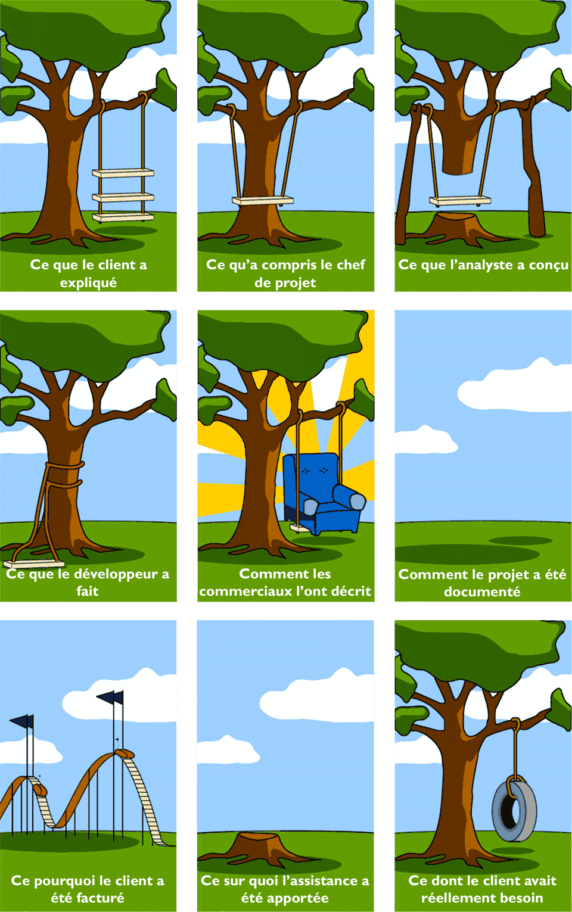



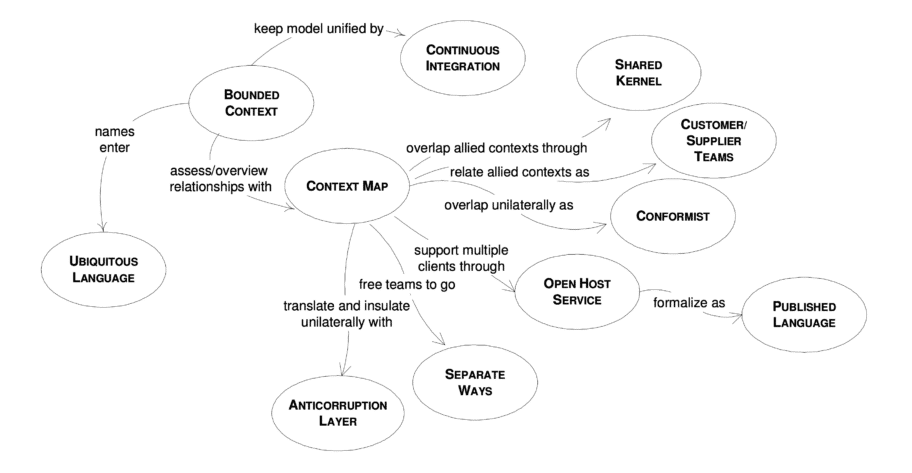
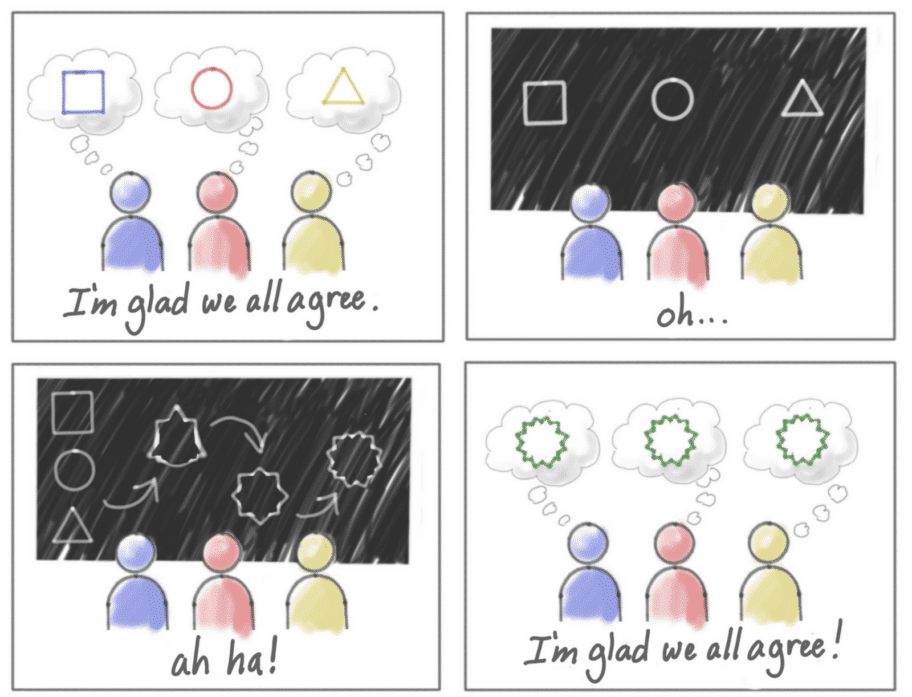
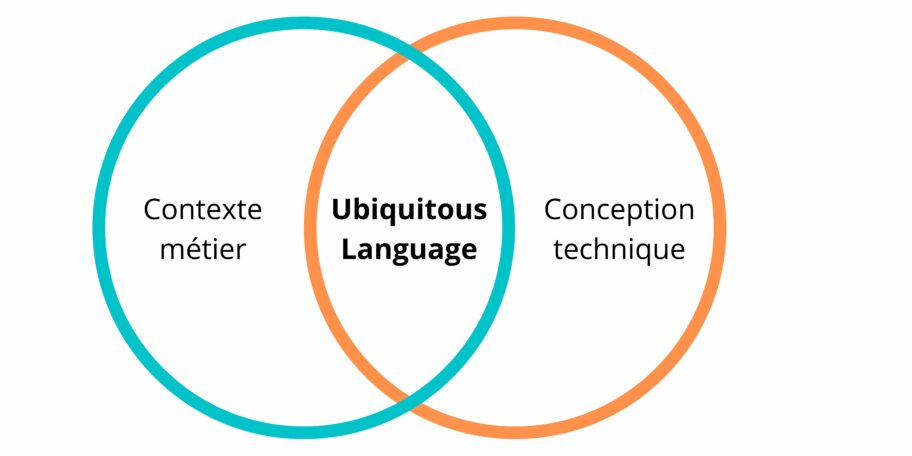
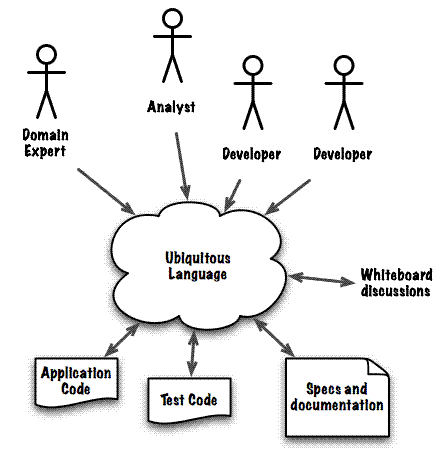
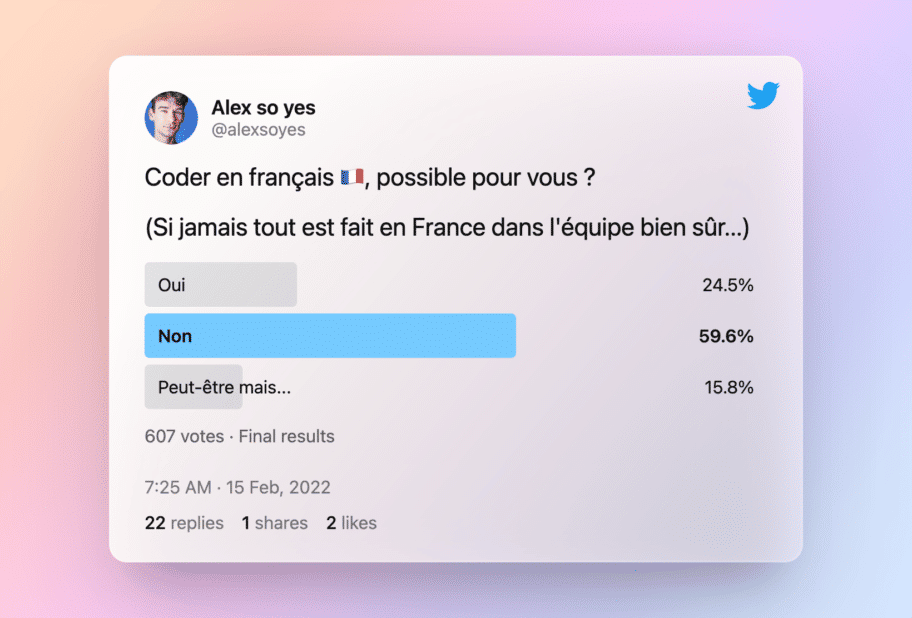

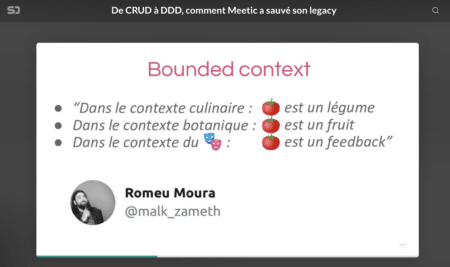
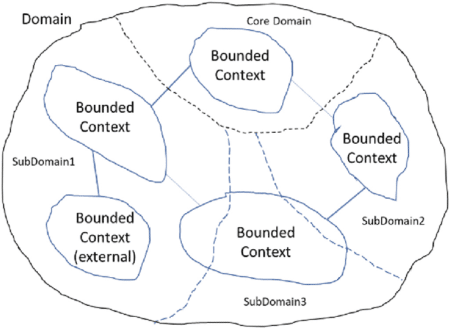
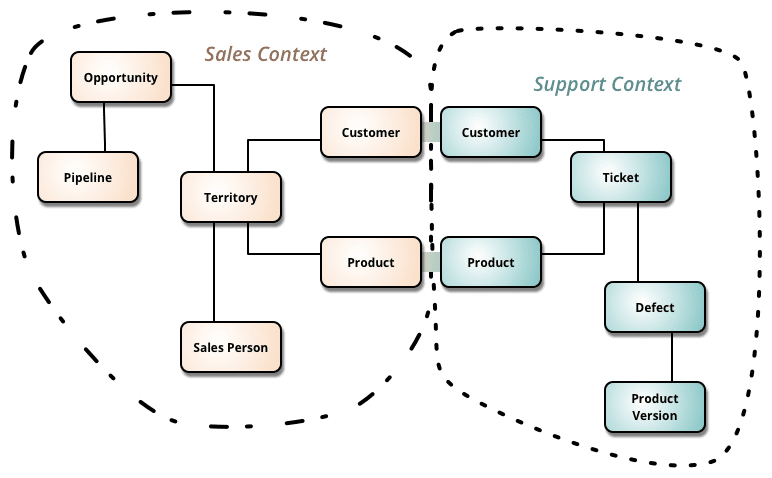

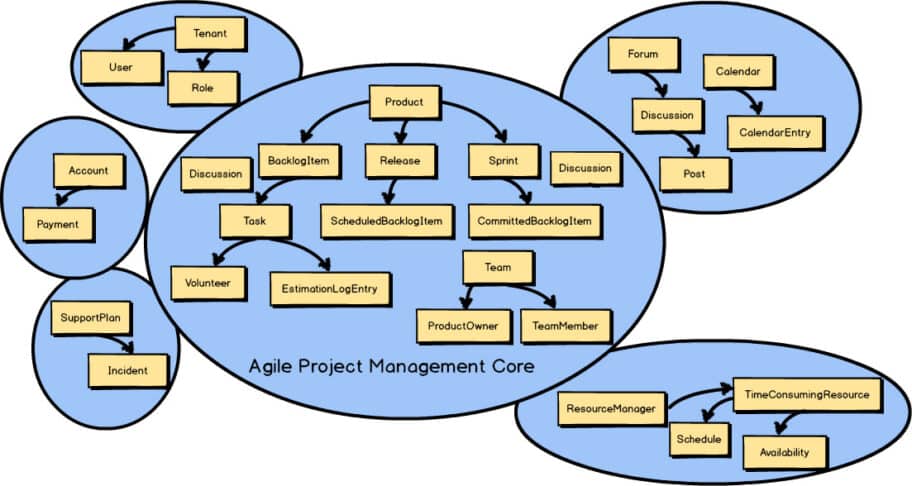
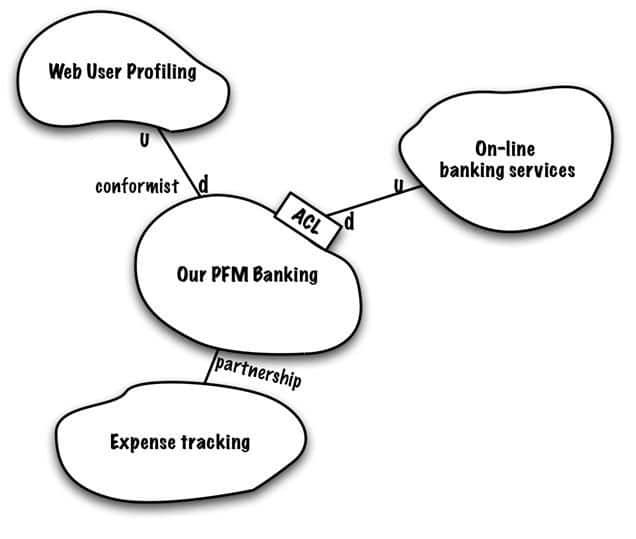
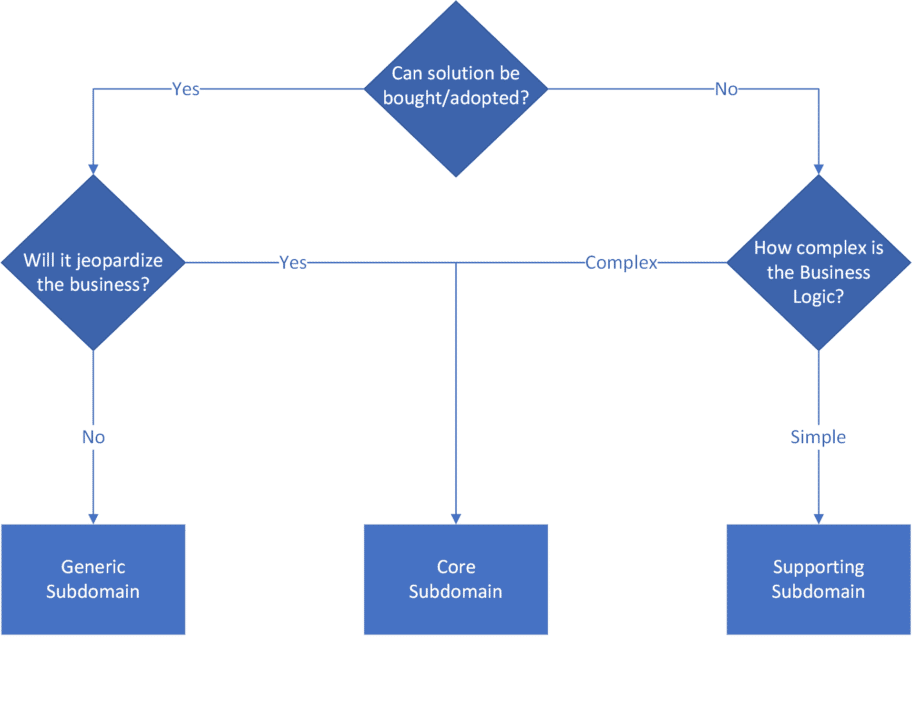
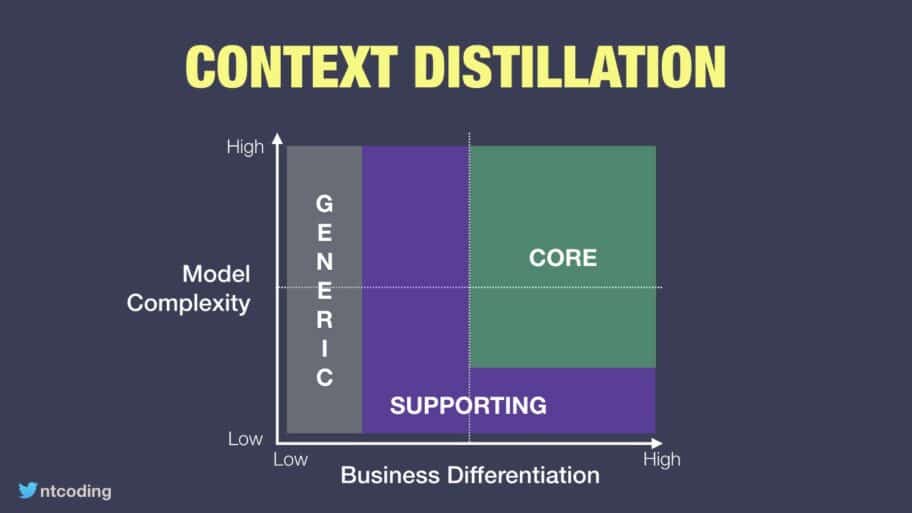
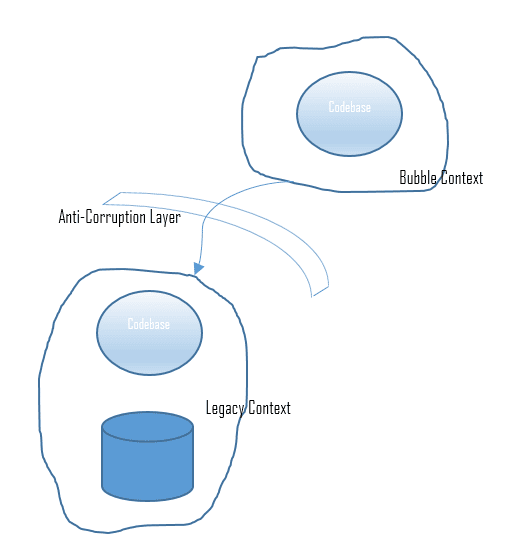
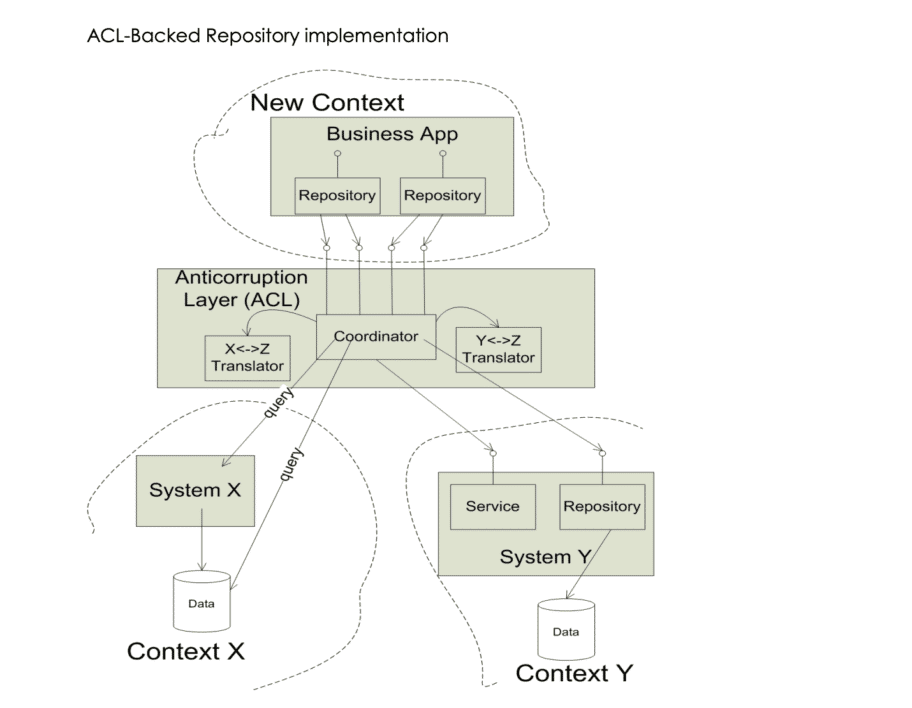



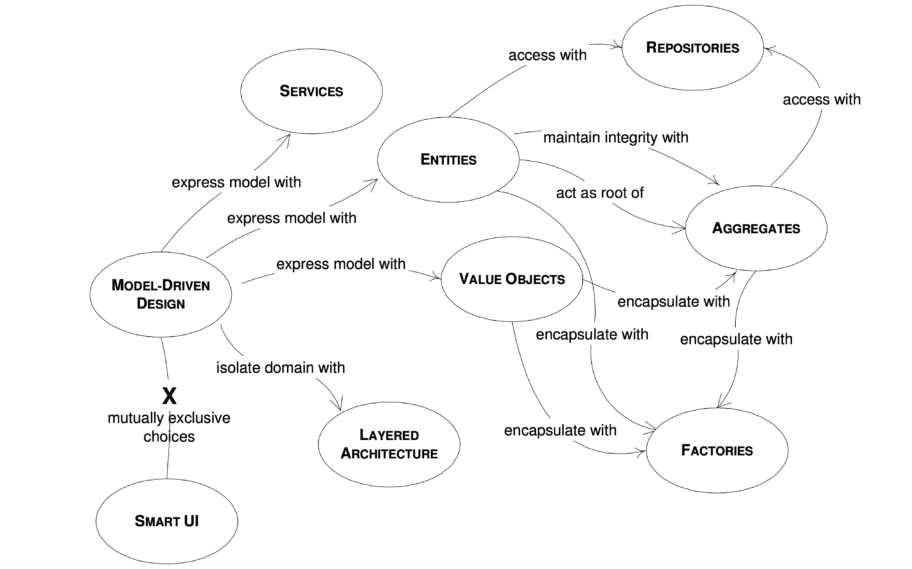
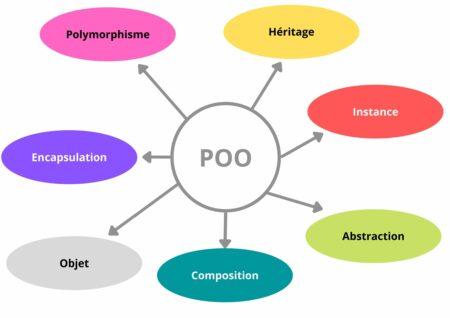

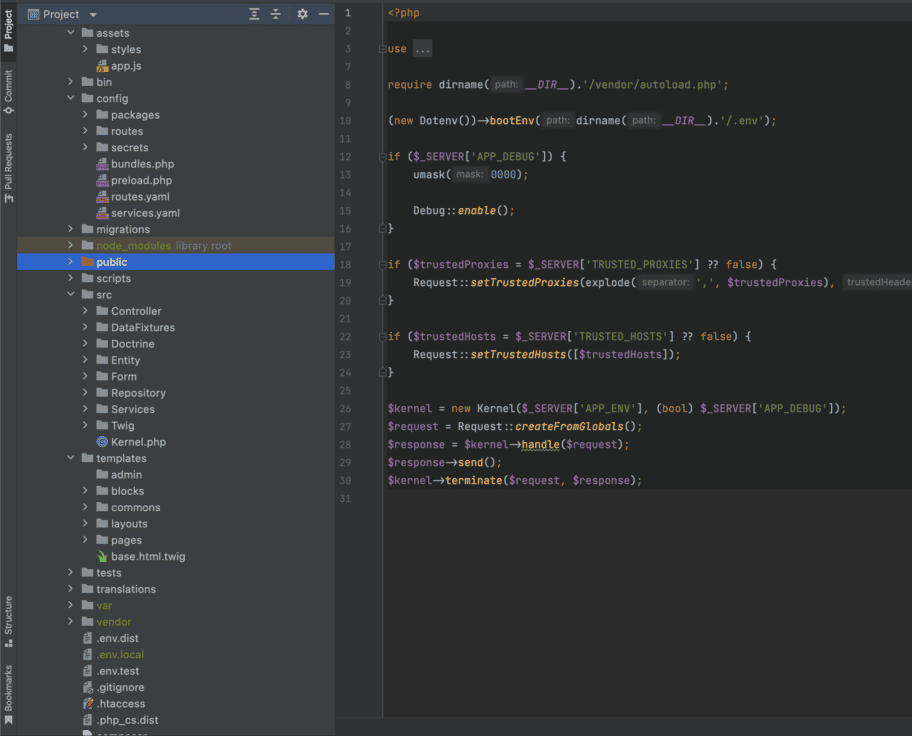
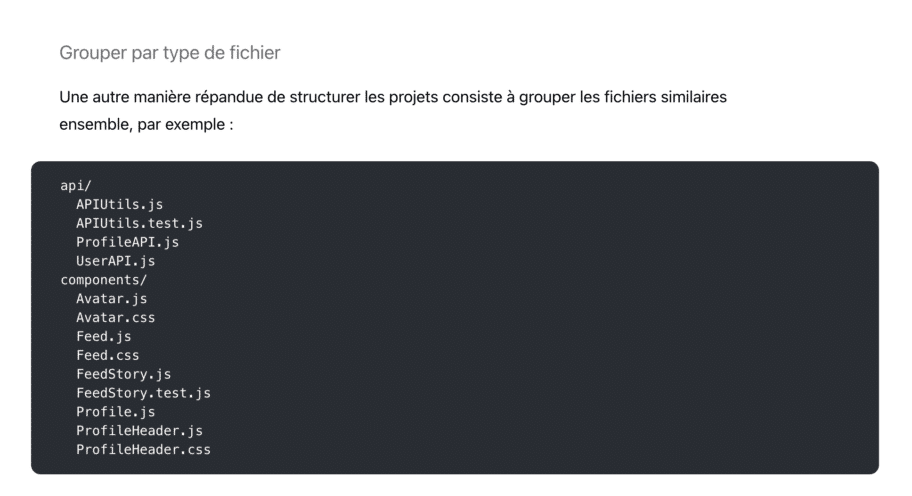
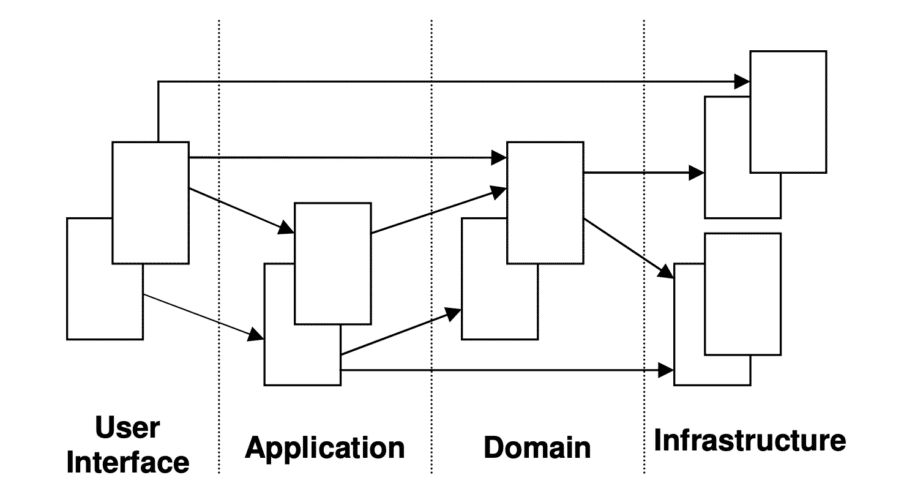
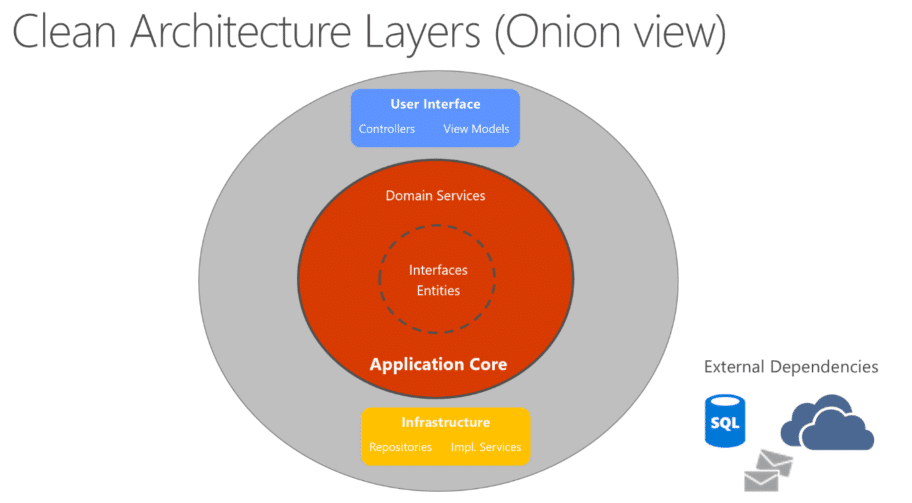
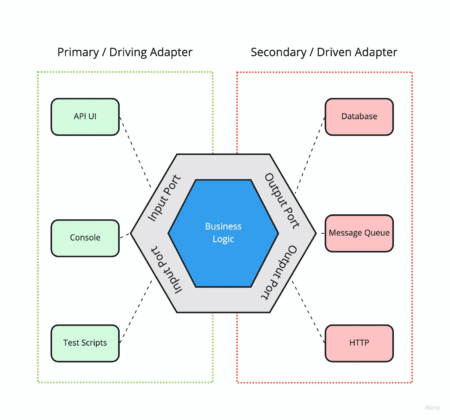
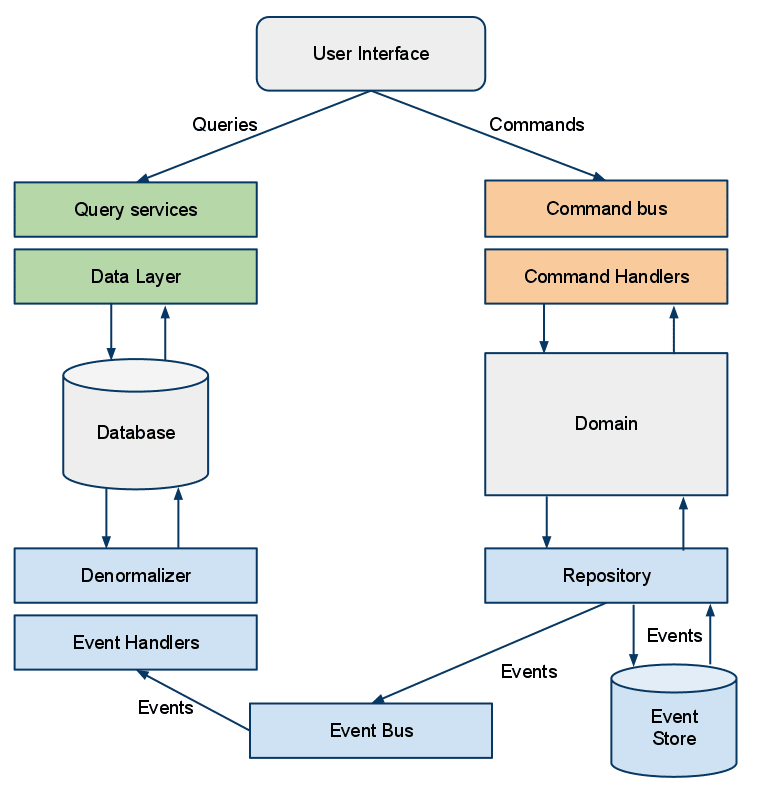

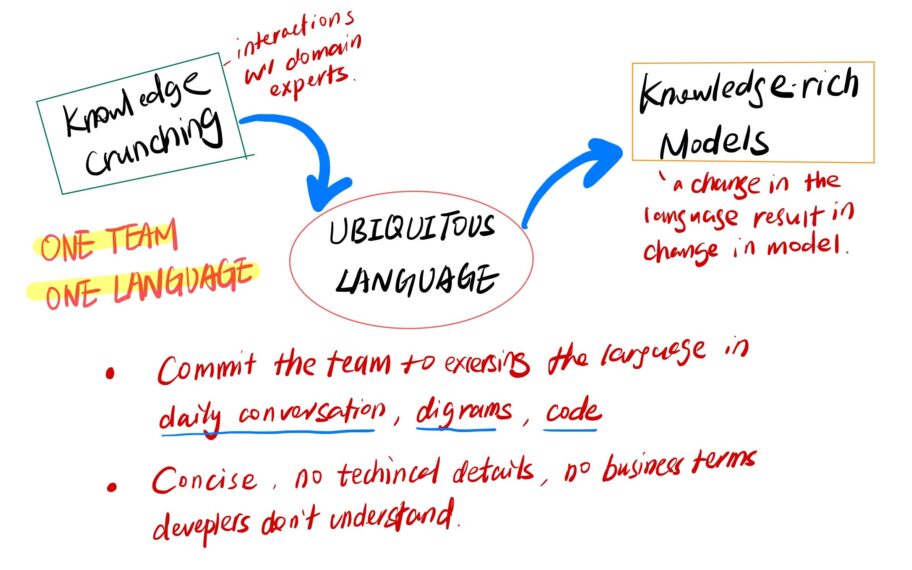


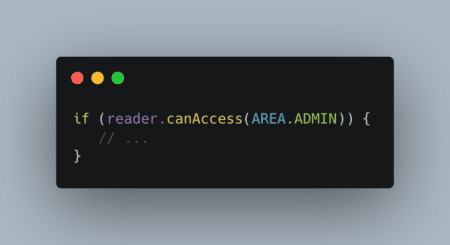
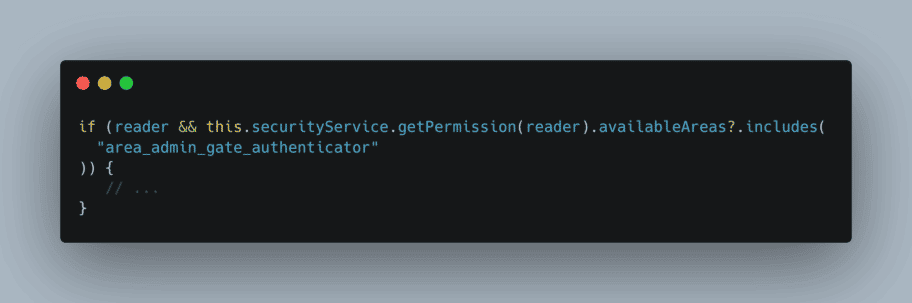
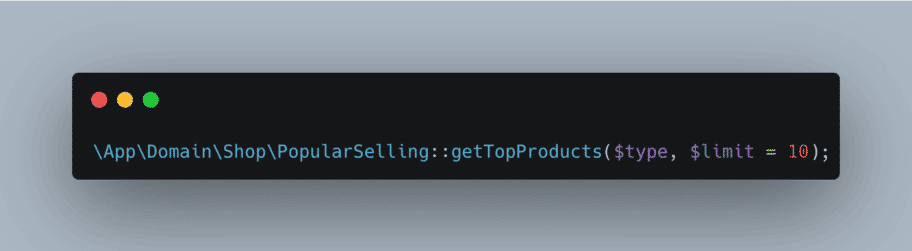









## DDD presque partout
J’avoue que depuis que j’ai découvert le DDD, j’applique au moins le design tactique presque partout (sauf peut-être pour un PoC).
C’est une structuration de mon code que je trouve logique et en fin de compte plus simple.
Certes, peut-être pas indispensable de créer des couches ACL avec les composants tiers et on peut faire l’impasse sur d’autres éléments qui prennent un temps qui n’est pas forcément rentable, même sur le long terme.
Évidemment, pour des projets simple, le temps passé sur du design stratégique, est plus difficile à justifier.
## Coût
Pas forcément d’accord… Du moins sur le moyen et long terme.
Mais comme tu l’indiques plus loin, c’est un investissement.
Si pour une entreprise, il n’y avait pas de ROI… alors l’investissement n’en vaut clairement pas la peine.
Non… Je pense que le facteur « coût » est réellement à relativiser.
Tout comme pour le TDD.
À long et même à moyen terme, il y aura moins de bugs ET, de part la conception en contextes découplés (si c’est bien fait), l’impact d’un bug sera en général nettement moindre.
Le code de l’application sera également plus facilement à maintenir, encore une fois, grâce au découplage. D’une part, il sera plus simple de faire la mise à jour de dépendances tiers, parce que tu auras pris soin d’ajouter une couche d’abstraction qui est précisément un ACL (donc, la plupart des correctifs se feront dans cet ACL).
D’autre part, si on parle du framework, qui fait parti de la couche infra, là aussi le découplage permet des mises-à-jour plus simples et donc plus rapide.
Facilité de mise à jour == moins de dette technique (qui elle coûte très cher à terme)
Aussi, le code sera plus facile à adapter ou à étendre pour répondre à un nouveau besoin business.
Plus de vélocité, plus de flexibilité…. plus de ROI.
Bref…
On est d’accord que quand on se lance, le développement sera plus lent et coûtera un peu plus cher…
Mais rapidement les bénéfices engendrés par le DDD surpassent ce coût additionnel (comme j’ai dit, comme pour le TDD)
## Shared Kernel
L’impression que tu simplifies un peu trop ici.
Le Shared Kernel n’est pas « juste » un value object que tu voudrais partager…
En fait pour ce genre de Value Objects (comme `EmailAddress` que tu mentionnes), j’ai tendance à les mettre dans un module `Common` puisque ce sont des composantes, comme des dépendances, que tu risques d’utiliser un peu partout.
Le Shared Kernel est un peu plus que ça. C’est un Bounded Context dont une partie des composantes (entités, value objects, comportements, fonctionnalités, etc) sont partagés avec un ou plusieurs autres Contextes.
Dans beaucoup de cas c’est pour éviter de dupliquer du code (parfois parce que c’est pas si simple que ça, par exemple si lié à du Legacy)
Exemple simple, un Context `User` qui gère aussi bien l’authentication, que ses données (mails, adresses, numéros de téléphone, date de naissance etc).
Si ton contexte `ExpeditionDeMarchandise` a besoin de l’adresse, en bon DDD, l’adresse de livraison devrait également se retrouver dans ce contexte.
Un Shared Kernel est quand `ExpeditionDeMarchandise` va directement utiliser les adresses des utilisateurs dans le contexte `User`.
Le Shared Kernel a une série d’avantages, notamment du code non dupliqué, mais engendre aussi les problèmes liés au couplage fort… Encore plus si plusieurs contextes utilisent ce Shared Kernel.
## Core – Support – Generic
Il y a quelque chose qui me dérange ici… Peut-être que c’est un peu trop résumé…
Personnellement, je préfère voir ça comme des couches dans le Business et chacun des trois est composé de différents domaines et sous-domaines qui vont, *in fine*, se décliné en Bounded Contexts.
Après, ce qui va se trouver dans ces différentes couches va énormément dépendre du contexte.
Par exemple, un soft comptable se trouvera dans presque tous les cas dans le Generic Domain… Sauf si tu es une agence de comptabilité où le logiciel, même s’il est acheté, va se trouver au centre de ton Core Domain.
En fin de compte, ce n’est pas la solution technique qui définit si un composant est core, support ou generic… C’est le métier…
Et comme tu l’as indiqué, c’est le métier qui pilote.
## POO
La programmation fonctionnelle se prête aussi très bien du DDD, d’une certaine façon, même mieux…
## Clean / Onion architecture et DDD
Note: attention que Eloquent est basé sur l’Active Record, pas Doctrine qui se base sur le Repository Pattern (je ne suis personnellement pas un grand fan du AR)
Ça a un impact considérable si on voulait switcher…
Ceci dit, il y a des devs, Laravel évidemment, qui font du DDD avec Eloquent, mais IMHO il serait nettement plus simple de basculer carrément sur du simple PDO.
## Comment gérer les dépendances entre les couches ?
Pense que tu devrais parler de la gestion d’Events (Domaines et Applicatifs) ici.
IMHO, c’est la meilleure approche pour éviter le couplage.
À ce sujet, pour PHP, jette un œil à EcoTone :
Il aide aussi énormément pour la mise en place du CQRS dont tu parles plus bas…
Tout passe par des `Bus` (`QueryBus`, `CommandBus` &, évidemment le `EventBus` pour les événements).
Moi je kiffe.
Merci pour ton commentaire super long et agréable 🙂
Je suis carrément d’accord avec toi sur le Design Tactique, car c’est avant tout du bon sens et des bonnes pratiques me concernant, je vais le préciser.
## Coût
Pour le coût, tu gagnes c’est sûr à la manière du TDD, mais je n’ai pas suffisamment d’expérience pour affirmer le contraire sur le DDD. En revanche tous les acteurs de la tech le disent, c’est plus couteux. Surtout j’imagine car les patterns stratégiques prennent beaucoup de temps, je pense que tu y gagnes sur les projets très complexes, sur les projets moyennement complexe si les méthodos de gestion de projet sont bien appliquées, a priori ça devrait aller. tu ne penses pas ?
Alors moi la partie clean architecture et séparation du code métier je suis absolument convaincu. J’avoue que ça flirt bien avec le DDD et ses patterns 🙂
## Shared Kernel
Sur le Shared Kernel tu as sans doute raison, en revanche je serais curieux de voir comment tes bounded contextes interagissent entre eux ?
Pour le coup la gestion des utilisateurs je la délèguerais bien à un contexte externe en dehors de l’app, et si jamais il y avait besoin de discuter avec des classes internes, je le ferais sans doute grâce à une interface.
Quand bien même l’utilisateur soit le même, j’aurais peut-être pensé à avoir 2 entités distinctes ici…
1 utilisateur qui passe 1 commande pour 1 point de livraison donné.
Afin de ne pas avoir d’info de commande dans le contexte User qui s’en balance. Je ne sais pas si c’est clair ou si je ne me suis pas égaré là 😀
## Core – Support – Generic
Tu entends quoi par couches ?
Ton exemple sur la comptabilité est super cool, je vais le faire remonter dans l’article car ça a beaucoup de sens.
## POO
Je vais creuser sur la FP, si il faut il y aura de beaux exemples !
## Clean / Onion architecture et DDD
T’as raison pour mon exemple sur le ORM, ça marche pas ! D’ailleurs j’aime pas l’AR non plus, j’en discutais au Web2Day hier avec un autre dev.
Je vais corriger ça, merci encore pour ta lecture 🙂
## Comment gérer les dépendances entre les couches ?
Cette partie était tellement longue et complexe que j’ai préféré ne pas trop l’aborder…
Mais ça va forcément fait l’objet d’un article un de ces quatre, c’est trop cool pour que je n’y aille pas 🙂
Encore MERCI pour ton commentaire super instructif !
Bravo pour cet article très complet !
Juste une remarque sur l’exemple donné pour les services :
« Par exemple, transférer de l’argent d’un compte à un autre.
Cette fonctionnalité ne peut pas se retrouver dans le compte qui débite ni celui qui crédite, par essence l’action doit se retrouver dans un service tiers. »
Pour moi, c’est plutôt l’exemple classique d’un aggregate « Transaction », puisqu’on voudra assurer l’intégrité du transfert.
L’utilisation d’un agrégat préserve la cohérence du système, en annulant le débit si le crédit échoue.
Hello Hervé !
Merci beaucoup pour ton message 🙂
Tu pourrais développer ? C’est grave intéressant ton exemple
Article bien dense , merci pour le partage !
Petite question , mais j’ai l’impression que ce que tu décris comme Factory ressemble plus à un builder ( même si ce pattern semble très utilisé en place du Factory dans le DDD)… Et si j’ai tord , je serai ravi de le savoir 🙂
Merci Max ! Tu veux bien développer sur la diff Factory vs Builder ? 🙂
Bravo Cet article est très intéressant et surtout très instructif pour un chef de projets aussi. Cette démarche s’inscrit parfaitement dans les objectifs de la méthode de gestion de projet (méthode Prince 🤴 2 par exemple)
Merci Charles !
Je ne connais pas du tout la méthode Prince, je vais me renseigner pour en parler via l’article sur les chefs de projet numériques 🙂
« Merci Max ! Tu veux bien développer sur la diff Factory vs Builder ? »
Je pense que ce qu’il veut dire c’est que l’exemple de la factory AnnonceFactory ressemble plus au pattern Builder que Factory.
Pour moi la factory (https://refactoring.guru/fr/design-patterns/factory-method) permet de retourner la bonne instance parmi plusieurs classes candidates,
alors que le builder (https://refactoring.guru/fr/design-patterns/builder) permet de créer un objet complexe par étapes,
étapes qui peuvent être guidées avec le pattern fluent builder (https://dzone.com/articles/fluent-builder-pattern).
Sinon super article avec pleins de source et ça c’est cool.
Je voudrais en partager une de plus le blog de Vladimir Khorikov alias https://enterprisecraftsmanship.com/
Sur ce blog il y a des articles qui sont pour moi des références comme par exemple :
https://enterprisecraftsmanship.com/posts/domain-model-purity-completeness/
https://enterprisecraftsmanship.com/posts/always-valid-domain-model/
Merci pour le partage, je vais prendre le temps de regarder tout ça, notamment cette histoire de builder qui me paraît un peu confuse de mon côté !
Vladimir Khorikov je l’ai vu passer dans mes recherches, « always valid domain model » je l’avais lu, tellement important…
Bravo ! beau boulot !
Je poursuis ma lecture … 🙂
Je viens de partager sur twitter et linkedin 😉
Trop sympa, merci pour ton message Jean-Jacques 🙏
Hello,
Excellent article qu’il me faudra relire plusieurs fois pour le contextualiser dans le vocabulaire de mon organisation et en extraire toute sa richesse.
Zoomons par exemple sur le modèle en couches, si tu le veux bien.
Ton découpage est : user interface + application + domaine + infrastructure
Dans notre langage corpo, nous découpons en : front-office (FO) + middle-office (MO) + orchestrateurs par domaine (ORK) + services élémentaires (SE) + back-office code métier et persistance (BO)
1 FO consomme 1 MO mais 1 MO peut être consommé par plusieurs FO
1 MO consomme 1 à n ORK, voire 1 à n SE directement.
1 ORK = 1 domaine, nous avons donc 1 ORK transverse. 1 ORK consomme 1 à n SE
1 SE consomme 1 BO
Dans un monde idéal, notre code métier devrait être uniquement dans les BO.
Mais dans la réalité, certaines règles métiers se trouve aussi dans le MO voire dans le FO ou l’ORK.
Exemples ?
Règles spécifiques à 1 FO d’une marque ou d’une population (parmi client final/courtier/agent/partenaireB2B…) => généralement codées dans le MO mais aussi parfois dans le FO. Cela dépend du nombre de FO connectés au MO et de la disparité des règles. C’est un de nos défauts 😉
Dans l’ORK, il peut y avoir des process métiers divergents de part l’historique des BO (le nouveau système d’assurance vie, celui d’avant, celui d’avant encore…).
Si l’urbanisation des SI était à 100% nous n’aurions pas ces verrues, mais cessions/acquisitions/rénovations etc… ne s’accompagnent pas toujours de cet effort.
Et dans la vraie vie, le nouveau système X remplace l’ancien système Y… à 80% car migrer les 20% restants vers X coûte trop cher
Au niveau de la data, les données vives du métier (les objets métiers comme proposition, contrat, prestation…) sont bien persistées dans les BO.
Mais nous avons aussi de la data dans les MO. Les paramètres applicatifs mais aussi les données de travail, celles collectées avant validation des objets métiers.
Du coup, j’ai du mal à faire matcher notre archi en couches et la tienne (surtout avec la vue Onion)
Et tout cas un grand merci pour ton partage !
Re !
T’as tout résumé…
Avant j’avais tendance à être assez extrême dans ma manière de coder et de voir l’architecture.
Désormais, je suis plutôt dans une optique de faire « au mieux en fonction des contraintes ».
Pour l’architecture hexagonal… J’ai parfois énormément de mal à dealer avec, notamment car elle rajoute une bonne couche de complexité là où certaines choses devraient être simples (notamment sur la DI).
De ce point de vue là, je t’invite à discuter avec Julien Topcu et Nicolas De Boose. J’ai beaucoup appris d’eux et je pense qu’ils auront plein de questions intelligentes à poser à tes questions 😉
Encore merci pour tes messages !
Au plaisir,
Alex
Bonjour,
Ton article est vraiment ultra-détaillé et inspirant.
J’en suis à sa 4ème lecture, mais je sens qu’il y a encore de la richesse à en extraire.
Dans mon organisation, nous nous targuons d’être DDD avec une architecture en couches.
Pourtant, certains symptômes ne font penser que tel n’est pas le cas.
J’ai donc tenté de projeter notre architecte sur le modèle que tu proposes, mais des incohérences apparaissent.
Sûrement dues à nos divergences de langage (le langage commun est déjà très difficile à fixer au sein d’une organisation, c’est encore plus compliqué entre plusieurs organisations) mais aussi par des réflexes (pavloviens ?) développés de notre côté.
Je crains d’être influencé par des biais de confirmation, car notre architecture est le résultat d’une longue réflexion, avec des fausses pistes, des remises en questions et des réorientations.
Si je t’expliquais notre architecture actuelle, serais-tu disposé à la regarder avec l’œil du candide ?
Comprendre, avec l’œil et l’esprit non pollués par nos biais ?
Soyons clairs, je n’ai pas de budget pour lancer une telle étude via un contrat formel.
J’imagine ta contribution à une grosse paire d’heures (au pire 4).
Je ne peux te promettre que de la visibilité sur Twitter et LinkedIn (oui c’est peu).
Je comprendrais donc ton refus, sans aucun souci.
Bien à toi,
@jeff_bourges sous Twitter
https://www.linkedin.com/in/jean-fran%C3%A7ois-gabarren-25b38057/ sous LinkedIn
Hey 🙏
Merci pour ton message !
La bonne architecture c’est celle qui correspond à tes besoins… C’est pour moi ce que le DDD essaye de transmettre, remettre le métier et ses besoins au coeur du code.
Et non pas se laisser dériver par un template ou une méthodologie rigide…
Honnêtement je ne suis vraiment pas certain de pouvoir vous aider.
Cet article est le fruit de 6 mois de recherche et je commence à peine à appréhender la chose dans sa globalité.
Bon courage pour vos recherches, et encore plus pour ton commentaire !