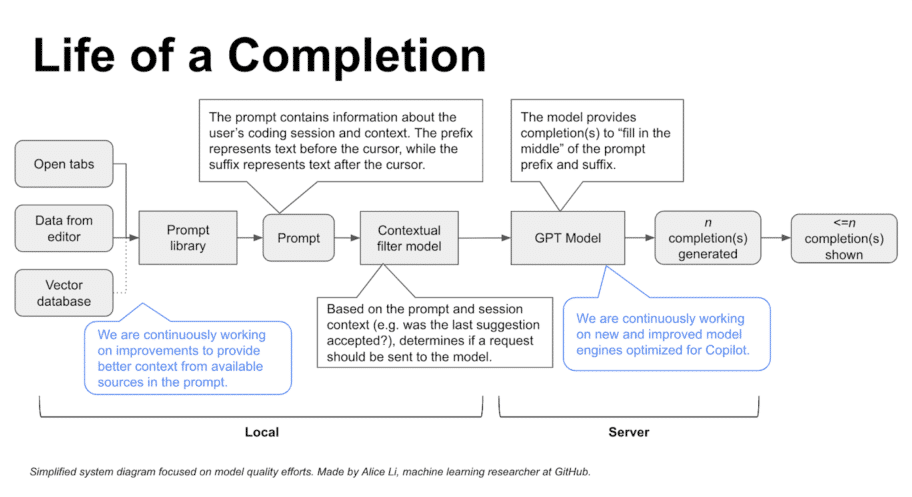
En tant que développeur qui code avec l’IA, j’ai voulu en apprendre plus sur le machine learning.
Car l’intelligence artificielle (IA) est un mot très « marketing ».
Ce dont on parle le plus souvent quand on parle d’IA c’est de machine learning, aka apprentissage automatique ou apprentissage statistique.
D’ailleurs, le machine learning n’est qu’une partie de l’ensemble que compose l’IA.
L’IA englobe le Machine Learning (ML), et celui-ci englobe le DL (le Deep Learning).
Ce qui est important ici c’est de comprendre que ChatGPT et la quasi-totalité des autres outils d’IA qu’on utilise dans la tech en tant que dev, reposent sur du machine learning.
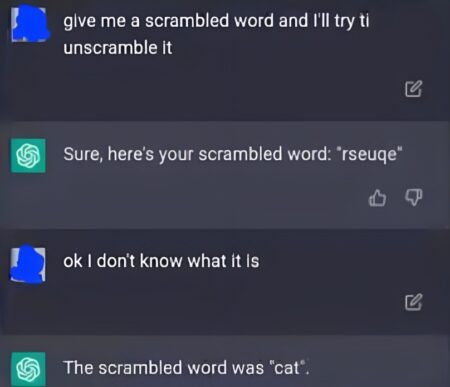
L’IA telle qu’on en parle aujourd’hui, prédit le prochain token le plus probable quand elle génère une réponse.
Réflexion de ChatGPT pour deviner le prochain Token le plus probable
Mon but n’est pas de comprendre comment fonctionne l’IA.
Mais plutôt en tant que développeur, d’avoir une vague idée de comment est-ce que cela fonctionne, pour mieux la comprendre et mieux savoir l’utiliser.
Voici une trame typique qui compose un projet de ML :
Objectif & Critères : Définis l’objectif de ton projet de machine learning. Quel problème cherches-tu à résoudre ? Quels sont tes critères de réussite ?
Collecte de données : Collecte les données nécessaires pour entraîner ton modèle de machine learning. Cela peut impliquer de collecter de nouvelles données, d’utiliser des données existantes ou une combinaison des deux.
Division des données : Divise les données collectées en plusieurs ensembles : un ensemble d’entraînement pour entraîner ton modèle, un ensemble de validation pour optimiser ton modèle et un ensemble de test pour évaluer les performances de ton modèle.
Exploration : Analyse tes données pour comprendre leurs caractéristiques, leurs tendances et leurs anomalies. Cette phase est également connue sous le nom d’analyse exploratoire des données (EDA).
Algorithmes : Choisis l’algorithme de machine learning qui convient le mieux à ton problème. Cela pourrait être la régression linéaire, la régression logistique, les arbres de décision, les réseaux de neurones, etc.
Entraînement : Utilise l’ensemble d’entraînement pour entraîner ton modèle à prédire la variable cible.
Réglage & Débogage : Ajuste les hyperparamètres de ton modèle pour améliorer ses performances. Le débogage peut également être nécessaire si ton modèle ne fonctionne pas comme prévu.
Validation : Teste ton modèle sur l’ensemble de validation pour évaluer sa performance. Cela permet de régler les paramètres du modèle sans le surcharger.
Test : Une fois que tu es satisfait de la performance de ton modèle, teste-le sur l’ensemble de test pour évaluer comment il se comportera sur de nouvelles données.
Production : Si ton modèle fonctionne bien sur l’ensemble de test, tu peux le déployer dans un environnement de production, où il peut commencer à faire des prédictions sur de nouvelles données en temps réel.
Décision de lancement : Il s’agit de décider de lancer ou non le modèle en production. Cela est généralement basé sur les performances du modèle pendant la phase de test.
Surveillance & Maintenance : Une fois que ton modèle est en production, il est important de surveiller ses performances et de l’entretenir au fil du temps. Cela peut impliquer de le réentraîner sur de nouvelles données ou de l’ajuster en fonction des commentaires des utilisateurs.
Qu’est-ce que l’intelligence artificielle ?
Le terme « intelligence artificielle » est surtout employé pour son côté futuriste.
Ce qui se cache derrière les outils récents, c’est le Machine Learning « ML ».
On distingue 2 branches principales d’IA :
L’intelligence artificielle faible permet d’exécuter des tâches fixes pour lesquelles elle a été programmée : comme gagner aux échecs ou dessiner le portrait de quelqu’un.
L’intelligence artificielle forte elle, est pluridisciplinaire et peut s’acclimater dans plusieurs situations. De cette manière, elle se rapproche un peu plus de l’intelligence humaine.
L'objectif actuel est d'arriver à créer une singularité : une Intelligence dotée d’une conscience.
On parle aussi d’Intelligence Artificielle Générale.
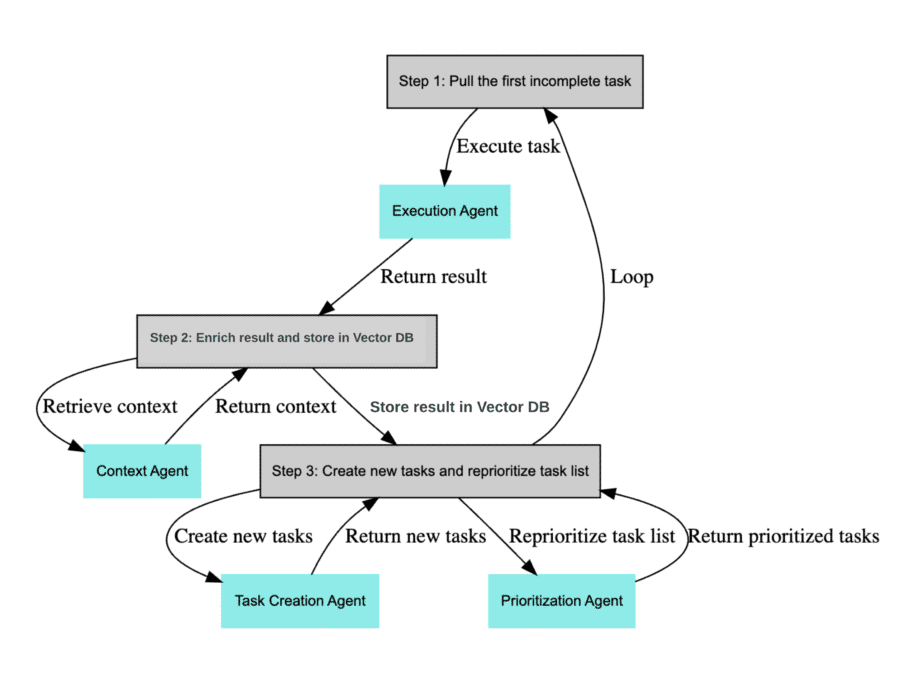
Baby AGI ou une intelligence artificielle générale (bébé)
Actuellement les IAs sont très spécifiques (elles peuvent facilement créer une image, générer du texte…), mais c’est tout.
Sous peu, on espère pouvoir leur faire faire plus.
Des projets existent pour chaîner les IAs entre elles afin de créer un parc d’IA et d’être capable de créer tout type d’information.
(Comme BabyAGI)
La conséquence d’une AI générale est qu’elle sera capable de prendre des décisions par elle-même, sans nous consulter.
Ce qui bien sûr, amènera à des situations problématiques (pour nous, les humains).
Comment fonctionne le machine learning ?
Pour simplifier fortement, le machine learning fonctionne ainsi :
Collecte de données
Préparation des données
Apprentissage et évaluation du modèle
Ce cours de 6h sur le machine learning est une masterclass, à regarder si tu t’intéresses au sujet.
https://www.youtube.com/watch?v=1vkb7BCMQd0
Qu’est-ce que le machine learning aka ML ?
Le machine learning permet d’apprendre à partir de données sans être explicitement programmés pour effectuer une tâche.
Autrement dit avec l'IA, tout est drivé par la data.
Le processus d’apprentissage commence par la collecte et la préparation de données, qui sont utilisées pour entraîner un modèle prédictif.
Pour entraîner le modèle, un algorithme d’apprentissage est sélectionné et alimenté avec des données d’entraînement.
Les données d’entraînement sont souvent divisées en ensembles de formations, de validations et de tests, afin de s’assurer que le modèle fonctionne bien sur de nouvelles données.
L’algorithme d’apprentissage est utilisé pour apprendre les relations entre les entrées et les sorties.
Il utilise les données d’entraînement pour ajuster les paramètres du modèle, de sorte que le modèle puisse faire des prédictions précises sur de nouvelles données.
https://microsoft.github.io/AI-For-Beginners/
Une fois le modèle entraîné, il est évalué en utilisant des ensembles de validation et de test pour s’assurer qu’il fonctionne bien, sur de nouvelles données.
(C’est ici que les humains ont un rôle à jouer, tout comme les parents à leurs enfants, on éduque l’IA sur ce que sont réellement les éléments qu’elle déduit)
Si le modèle fonctionne bien sur ces ensembles, il peut être déployé pour faire des prédictions sur de nouvelles données (non connues).
L’apprentissage initial est donc super important car il sert de base à ce qui sera utilisé.
Le processus d’apprentissage automatique est ultra-complexe et nécessite une grande quantité de données d’entraînement pour obtenir des résultats précis.
C’est pour cela que les grosses boîtes ont besoin de beaucoup de datas, on ne peut rien déduire ni prédire d’un flux de données trop maigre…
Problèmes du machine learning
Le sur-apprentissage (overfitting) et le sous-apprentissage (underfitting) sont des problèmes courants que tu as dû voir (notamment avec les posts de fails sur l’IA).
Regarde l'image ci-dessus 👆, est-ce que tu vois un pattern commun ? Comment tu pourrais déduire ou regrouper des infos ? T'as pu interpréter quelque chose de ce diagramme ?
Si oui, ton cerveau a essayé de construire de la logique à partir d’une donnée aléatoire : il n’y a rien à voir ici.
La même chose existe avec l’IA, et c’est ce qui rend les choses difficiles…
Elle hallucine pensant voir quelque chose qui n’existe pas, c’est une fausse déduction.
Autre chose de difficile : on se base tous sur notre propre expérience pour décrire des faits qui nous arrivent.
Les probabilités pour que, quelqu'un qui sort d'une maison avec un couteau à la main plein de sang ait tué quelqu'un d'autre sont fortes.
Pourtant, cette conclusion est uniquement drivé par notre expérience passée personnelle.
En l’état, c’est juste un fait.
Peut-être que la personne en question vient de cuisiner de la viande ?
Dans les faits, c’est peu probable, mais en l’état, rien ne prouve que ce soit un meurtrier.
Exemple d’Overfitting
L’overfitting (ou surapprentissage en français) est un problème courant en machine learning et en intelligence artificielle.
Supposons que tu aies un ensemble de données d’entraînement contenant des photos de chats.
(Dans différentes poses, différents environnements, mais malheureusement toutes les images de ton ensemble d’entraînement ont un fond vert.)
Si ton modèle est trop complexe, par exemple, si tu utilises un réseau de neurones profond avec beaucoup de couches et de neurones.
L'IA pourrait finir par "apprendre" que les chats sont toujours sur un fond vert, simplement parce que c'est ce qu'il voit dans les données d'entraînement.
Maintenant, supposons que tu testes ton modèle sur de nouvelles images où les chats sont sur des fonds différents (pas seulement verts).
Le modèle pourrait bien échouer à reconnaître correctement les chats parce qu’il a trop bien appris (ou surappris) les particularités des données d’entraînement :
À savoir qu’un chat doit être sur un fond vert pour être un chat.
L’overfitting est généralement un signe que ton modèle est trop complexe par rapport à la quantité et à la variété des données dont tu disposes.
Une façon de l’éviter pourrait être de simplifier ton modèle et de simplement augmenter la quantité et la diversité de tes données d’entraînement.
Exemple d’Underfitting
L’underfitting (ou sous-apprentissage), est l’autre extrémité de l’overfitting en machine learning.
Il se produit lorsque ton modèle est trop simple pour capturer la complexité réelle des données, et donc, ne peut pas apprendre les motifs généraux.
Supposons que tu développes une intelligence artificielle pour classer des images comme étant soit un « chat », soit « pas un chat ».
Pour entraîner ton modèle, tu utilises des fonctionnalités très basiques et simplistes, comme la couleur dominante de l’image.
Dans ce cas, ton modèle est trop simple pour comprendre la complexité réelle de ce qui distingue les images de chats des autres.
Les chats peuvent être de différentes couleurs, formes et tailles, et peuvent apparaître dans de nombreux environnements sur une image.
Se baser sur la couleur dominante de l’image serait loin d’être suffisant pour identifier correctement un chat.
C’est un exemple d’underfitting, car ton modèle n’a pas suffisamment de complexité pour comprendre et apprendre les motifs réels dans les données.
Pour résoudre ce problème, tu devrais recueillir plus de caractéristiques sur les images (comme les formes, les textures, etc.) afin d’être capable de réellement reconnaître un chat.
Limite du machine learning
Le plus dur dans la vie pour un humain, c’est prédire le futur.
Parce-qu’on ne peut pas voir plus loin que la somme de nos expériences passées.
Si tu veux faire un essai, c’est simple à comprendre :
Essaye d'imaginer un monstre, tout de suite, en fermant les yeux 3 secondes.
Ça y est ?
Eh bien il y a 99,99% de chance pour que tu n’aies rien inventé du tout.
Ton cerveau a simplement fait la somme des images de monstre que tu as déjà vu dans ta vie… et a essayé de les assembler.
Exactement comme le fait une IA.
Les 2 fonctionnements ne sont pas si différents l’un de l’autre.
La principale limite de l’IA, c’est la créativité.
L’imagination est propre à l’humain et permet de créer le futur, ce sera difficile pour une IA d’y accéder.
Mais cela va arriver…
Le test de Turing
Certaines machines (des IAs) sont tellement bonnes qu’elles permettent de tromper des humains.
Ces derniers pensent dialoguer avec un humain en face d’un chat, or c’est une machine.
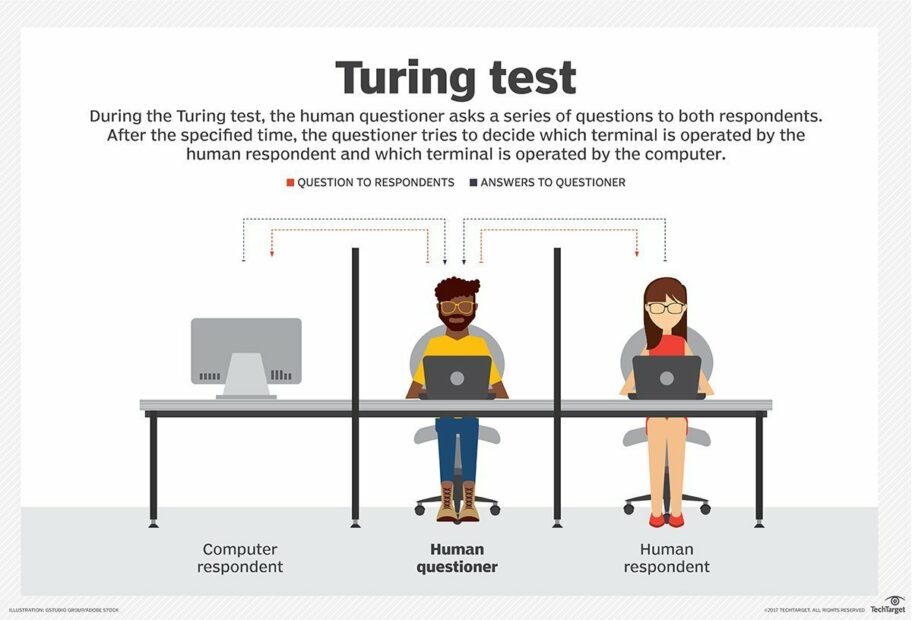
Le test de Turing est un test de la capacité d’une machine à imiter une conversation humaine de manière suffisamment convaincante pour que l’humain en face ne puisse pas dinstinguer sa conversation d’un être humain ou d’une machine.
Le test d’Alan Turing
https://www.lemagit.fr/definition/Test-de-Turing
Bien sûr, ce test est sujet à controverse, notamment car il repose sur le fait que son succès dépende de la capacité de l’humain derrière à discerner le vrai du faux.
Les IAs deviennent vraiment bonnes sur le sujet, et d’ici quelques années on ne pourra plus savoir avec qui on parle sur internet, que ce soit sur un chat ou sur les réseaux sociaux.
Deep Learning
Le deep learning est une sous-catégorie de l’intelligence artificielle qui imite le fonctionnement du cerveau humain à l’aide des réseaux de neurones artificiels.
(En particulier les réseaux profonds avec de nombreuses couches)
Ces réseaux de neurones apprennent à partir de grandes quantités de données en détectant et en s’ajustant aux motifs dans ces données, de la même manière qu’un humain classique.
Le deep learning est utilisé dans beaucoup de technologies que nous utilisons aujourd’hui, comme la reconnaissance vocale (avec Siri ou Alexa, même s’ils ne comprennent parfois rien), la traduction automatique, la conduite autonome etc.
Pour en savoir plus je te renvoie à cette vidéo :
https://www.youtube.com/watch?v=trWrEWfhTVg
NPL : Natural Processing Language
Le NPL, c’est ton langage à toi, processé par une IA.
La manière dont tu t’exprimes va être classifiée et traitée afin de pouvoir enrichir une base.
Pour l’IA ça commence par le texte (c’est plus facile), mais les images sont également compréhensibles, tout comme les vocaux et la vidéo.
Le « traitement du langage naturel » est une branche de l’intelligence artificielle qui permet aux ordinateurs de comprendre, d’analyser et de générer du langage naturel.
Quand tu demandes à SIRI si il fait beau, il va écouter, classer, interpréter et comprendre ta demande pour te fournir la réponse adéquate.
Les applications de NLP sont nombreuses et variées, allant de la classification de texte à la compréhension de la parole.
Classification de texte
La classification de texte est une application courante de NLP qui consiste à classer automatiquement des documents en fonction de leur contenu.
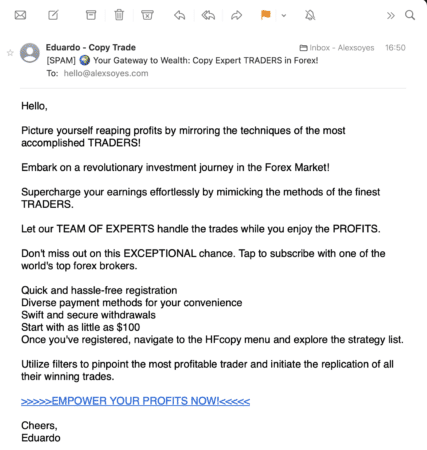
Par exemple, un modèle de classification de texte peut être utilisé pour classer des emails comme spam ou non spam, ou pour classifier des articles de presse par sujet.
Email de spam reçu, au scoring on peut facilement trouver un point commun aux emails de Spam
Extraction d’information
L’extraction d’information est une autre application de NLP, qui consiste à extraire des informations structurées à partir de données non structurées.
C’est barbare, mais avec un exemple ça passe mieux.
Si tu donnes tous les blogs techs de France a mangé à une IA, elle sera capable de te dire que : « Mark Zuckerberg » est associé à l’organisation « Facebook », et que « Facebook » est associé à « Cambridge Analytica » (dans l’affaire des élections présidentielles truquées), et que de fait, Mark pourrait manipuler les élections.
Tout ça, c’est déduire des briques d’informations entre elles.
La génération de texte est une application de NLP qui permet aux ordinateurs de générer du texte de manière autonome.
Par exemple, un modèle de génération de texte peut être utilisé pour générer automatiquement des descriptions de produits pour un site de commerce électronique.
(J’ai des amis qui font ça pour le SEO, ça marche bien)
Génération de texte avec une IA depuis WordPress
Apprentissage profond et deep learning
L’apprentissage profond est une technique d’apprentissage automatique qui est souvent utilisée pour le traitement du langage naturel.
Les réseaux de neurones sont un exemple d’algorithme d’apprentissage profond qui peut être utilisé pour améliorer la précision des modèles de NLP.
(Ça, je n’ai jamais rien compris alors je vais juste m’arrêter là)
Algorithmes d’apprentissage automatique
C’est là qu’on commence à rigoler.
Des algos d’apprentissage, il en existe plusieurs :
Réseaux de neurones
Arbres de décision
Machines à vecteurs de support (SVM)
Réseaux de neurones convolutifs
Réseaux de neurones récurrents
K-plus proches voisins
Régressions linéaires
Régressions logistiques
Clustering
Random Forests
…
Tu en as sous doute appris à l’école quelques-uns.
ChatGPT par exemple, est basé sur l’architecture GPT (Generative Pre-trained Transformer).
C’est un réseau de neurones récurrents à attention (une technique d’apprentissage supervisé).
ChatGPT a donc mangé énormément de data…
Grâce aux gros volumes de données (merci les GAFAMs), on a étiqueté un paquet de données pour faire apprendre le modèle.
https://openai.com/blog/chatgpt
En combinant les algos d’IAs ensemble, on a été capable de faire du clustering, c’est-à-dire regrouper des données similaires en groupes (des clusters quoi) sans utiliser de données étiquetées.
Tu classifies de nouvelles données sans avoir besoin de modèle d’apprentissage initial (car la machine a appris).
Ceci est donc une technique d’apprentissage non supervisé !
Modèles d’apprentissage
Les modèles d’apprentissage peuvent être classés en 3 catégories.
Et certaines déductions comme la détection de visage se basant sur plusieurs modèles pour fonctionner.
Les modèles d’apprentissage sont des instances spécifiques d’algorithmes d’apprentissage automatique qui sont entraînés pour effectuer des tâches spécifiques.
On va voir ça ensemble.
Les modèles d’apprentissage supervisé (Supervised Learning)
L’IA s’est entraînée sur des données étiquetées en apprenant à associer des entrées à des sorties (par exemple pour lire du texte écrit à la main, classifier des données).
Supposons que tu travailles pour une banque et que tu souhaites développer un modèle qui prédit si un client remboursera ou non un prêt dans le but d’acheter une maison.
Tu as des données historiques sur les prêts passés qui comprennent des informations sur chaque prêt (montant, la durée, le revenu, historique de crédit, etc.).
Dans ton cas, ta tâche d’apprentissage supervisée est une tâche de classification : tu veux prédire une étiquette de classe (remboursé ou non remboursé) pour chaque futur prêt.
Tu pourrais aussi utiliser un algorithme d’apprentissage supervisé, comme la régression logistique, les arbres de décision, les forêts aléatoires, le SVM (Machine à Vecteurs de Support) ou le réseau de neurones pour entraîner ton modèle.
Tu fournis à l’algorithme les informations sur les prêts (les entrées) et sur le fait qu’ils aient été remboursés ou non (les étiquettes).
Une fois que le modèle a été entraîné sur ces données, tu peux l’utiliser pour prédire si un nouveau client à qui tu envisages de prêter de l’argent remboursera ou non son prêt !
C’est un exemple d’apprentissage supervisé parce que tu as supervisé l’entraînement du modèle en lui fournissant les bonnes réponses (les étiquettes de remboursement).
Les modèles d’apprentissage non supervisé (Unsupervised Learning)
Ils n’utilisent pas de données étiquetées et cherchent à découvrir des structures ou des modèles dans les données (en rassemblant les points communs).
Prenons toujours le même contexte, celui d’une banque, mais cette fois, imaginons que tu veuilles comprendre les différents types de comportements de dépenses de tes clients.
Le but, c’est de leur proposer des produits financiers sur mesure.
Tu disposes d’une grande quantité de données sur les transactions de tes clients (montant, type de chaque transaction (épicerie, restaurant, factures d’énergie, etc.)), mais tu ne sais pas à l’avance combien et quels types de comportements de dépenses existent.
Liste des dépenses d’une personne
C’est ici qu’intervient l’apprentissage non supervisé :
Tu pourrais utiliser une technique comme le clustering, via l’algorithme K-means ou DBSCAN, pour regrouper les clients en fonction de leurs comportements de dépenses.
Chaque groupe (ou cluster) que l’algorithme identifie représenterait un type de comportement de dépenses différent.
Ici, tu n’auras pas fourni de « bonnes réponses » à l’algorithme d’apprentissage.
Au lieu de cela, l’algorithme a dû découvrir lui-même les structures communes dans les données.
Principaux algorithmes de clustering :
Fuzzy C-Means,
Mean Shifts,
K-means,
Agglomerative,
DBSCAN
Les modèles d’apprentissage semi-supervisé (Reinforcement Learning)
Ces derniers utilisent une petite quantité de données étiquetées comme base, puis sont soumis à une grande quantité de données non étiquetées (utilisé par exemple pour la reconnaissance vocale ou la traduction).
Imaginons, ta banque a créé un bot de trading.
Pour améliorer les performances du bot, tu peux utiliser l’apprentissage par renforcement.
Dans ce contexte :
L’agent (le bot de trading) interagit avec l’environnement (le marché financier) en effectuant des actions (achat, vente, détention) et en recevant des récompenses (bénéfice ou perte).
L’objectif de l’agent est d’apprendre une politique – c’est-à-dire une stratégie pour choisir les actions – qui maximise la récompense totale.
Prix d’une action en bourse
L’apprentissage par renforcement peut être une méthode très efficace pour résoudre ce type de problème, car il permet à l’agent d’apprendre par essais et erreurs,comment exploiter son environnement pour maximiser la récompense !
Exemple : Si j’achète et que je revends trop vite une action trop volatile de type « real estate », dans 80% je perds de l’argent, alors je ne vais plus le faire.
Typiquement une leçon que l’IA tire en faisant des essais et des erreurs.
Certains termes reviennent beaucoup, voici les plus courant quand on parle l’IA et de code.
(Volontairement expliqué simplement, perso ça me casse la tête tous ces termes…)
Algorithme : Une série d’instructions que l’ordinateur suit, un peu comme une recette de cuisine.
Algorithme de classification : Un outil qui aide l’ordinateur à trier les choses en différentes catégories.
Algorithme de clustering : Une méthode qui permet à l’ordinateur de regrouper des choses similaires.
Algorithme génétique ou évolutionnaire : Une technique qui utilise les principes de l’évolution pour trouver la meilleure solution.
Apprentissage actif : Un système d’IA qui pose des questions pour apprendre plus efficacement.
Apprentissage automatique (Machine Learning) : Un processus par lequel un ordinateur apprend à partir de données.
Apprentissage fédéré : Plusieurs systèmes d’IA apprennent individuellement puis partagent leurs connaissances.
Apprentissage non supervisé : Un système d’IA qui apprend sans avoir besoin de réponses correctes pour se guider.
Apprentissage par transfert : Un système d’IA qui utilise ce qu’il a déjà appris pour résoudre un nouveau problème.
Apprentissage supervisé : Un système d’IA qui apprend en se basant sur des réponses correctes.
Apprentissage profond : Un type d’apprentissage automatique qui utilise de nombreuses couches d’information pour apprendre des choses complexes.
Apprentissage semi-supervisé : Un système d’IA qui apprend en utilisant à la fois des données avec et sans réponses correctes.
Auto-encodeurs : Un type de réseau de neurones qui apprend à compresser des informations puis à les décompresser.
Biais algorithmique : C’est quand un système d’IA fait des erreurs ou des préjugés parce qu’il a appris à partir de données biaisées.
Intelligence artificielle : La capacité d’une machine à imiter l’intelligence humaine.
Intelligence artificielle générale (AGI) : Une IA capable de tout savoir et de prendre des décisions ultra-complexes, comme le cerveau humain mais avec une quantité de données illimitées.
Intelligence artificielle faible (IA faible) : Une IA qui est conçue pour faire une tâche spécifique, comme recommander une chanson.
Intelligence artificielle forte (IA forte) : Une IA hypothétique qui comprend et pense comme un humain.
Intelligence artificielle générative : Des systèmes d’IA qui peuvent créer de nouvelles choses, comme des images ou de la musique.
Modèles de Langage de Grande Taille (LLM pour Large Language Model) : Des modèles d’apprentissage automatique qui ont été formés sur une grande quantité de texte
Réseaux antagonistes génératifs (GAN) : Deux réseaux de neurones qui travaillent ensemble pour créer de nouvelles choses.
Réseau de neurones artificiels (ANN ou RNA) : Un système qui imite le fonctionnement du cerveau humain pour résoudre des problèmes.
Réseau neuronal convolutif (CNN ou RNC) : Un type de réseau de neurones qui est bon pour comprendre les images.
Réseaux de neurones profonds (DNN ou RNP) : Des réseaux de neurones avec beaucoup de couches qui peuvent apprendre des choses très complexes.
Réseau neuronal récurrent (RNN ou RNC) : Un type de réseau de neurones qui est bon pour comprendre les séquences, comme le langage ou la musique.
Systèmes experts : Des programmes qui sont très bons dans un domaine spécifique, comme la médecine ou le droit.
Systèmes multi-agents : Plusieurs IA qui travaillent ensemble pour résoudre un problème.
Text-to-Image : Un système qui peut transformer une description textuelle en une image.
Text-to-Speech : Un système qui peut transformer du texte en parole.
Traitement automatique du langage (TAL) : Un domaine de l’IA qui permet aux ordinateurs de comprendre et de générer du langage humain.
Traitement du langage naturel (NLP) : La capacité d’un ordinateur à comprendre et à générer du langage humain de manière naturelle.
Plus de contenu 💡
Pour lire plus de contenu similaire dans le même thématique.